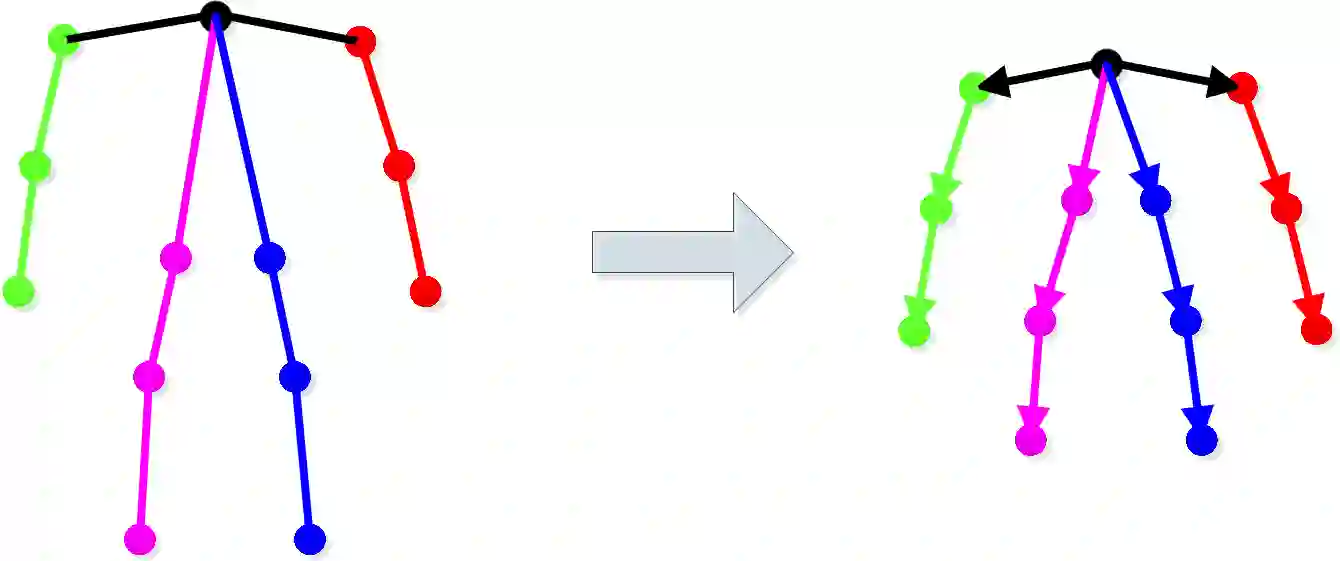
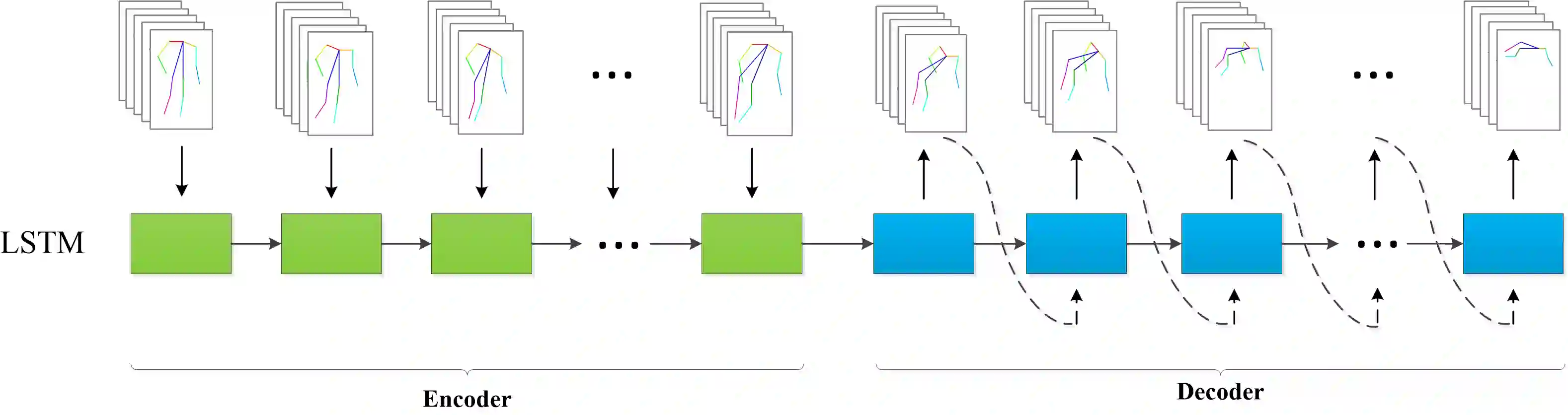
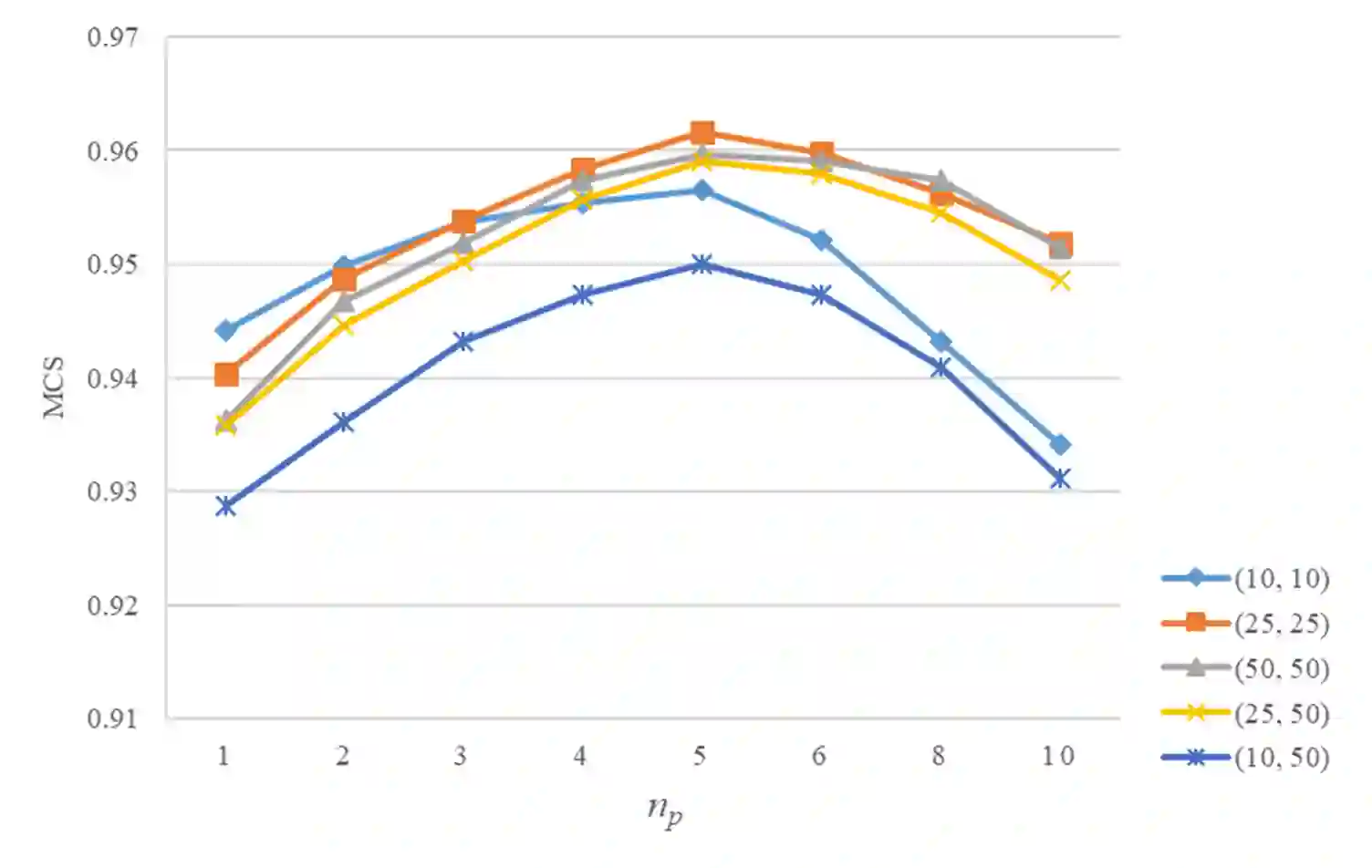
This paper presents a novel approach for predicting the falls of people in advance from monocular video. First, all persons in the observed frames are detected and tracked with the coordinates of their body keypoints being extracted meanwhile. A keypoints vectorization method is exploited to eliminate irrelevant information in the initial coordinate representation. Then, the observed keypoint sequence of each person is input to the pose prediction module adapted from sequence-to-sequence(seq2seq) architecture to predict the future keypoint sequence. Finally, the predicted pose is analyzed by the falls classifier to judge whether the person will fall down in the future. The pose prediction module and falls classifier are trained separately and tuned jointly using Le2i dataset, which contains 191 videos of various normal daily activities as well as falls performed by several actors. The contrast experiments with mainstream raw RGB-based models show the accuracy improvement of utilizing body keypoints in falls classification. Moreover, the precognition of falls is proved effective by comparisons between models that with and without the pose prediction module.
翻译:本文介绍了一种新颖的方法,用于预测通过单向视频提前坠落的人。 首先,观测到的框架中的所有人都被检测并跟踪,同时提取其身体键点的坐标。 一种关键点矢量化方法被用于消除初始坐标代表中不相干的信息。 然后, 观察到的每个人的关键点序列被输入到根据序列到序列(seq2seq)结构进行调整以预测未来关键点序列的构成预测模块中。 最后, 预测的姿势由下降分类器分析, 以判断一个人今后是否会下降。 构成的预测模块和秋点分类器使用Le2i数据集单独培训并联合调整, 该数据集包含191个关于各种正常日常活动以及若干行为者所完成的下降的视频。 与主流原始RGB模型的对比实验显示,在跌分级中,使用身体键点的准确性得到了提高。 此外, 与不使用形状预测模块的模型相比较证明, 跌落点的识别是有效的。