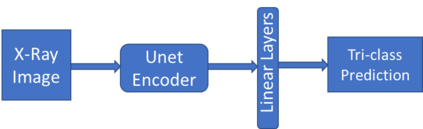
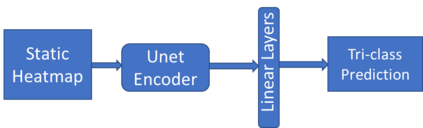
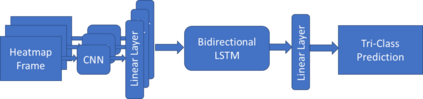
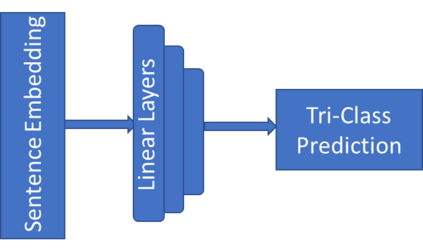
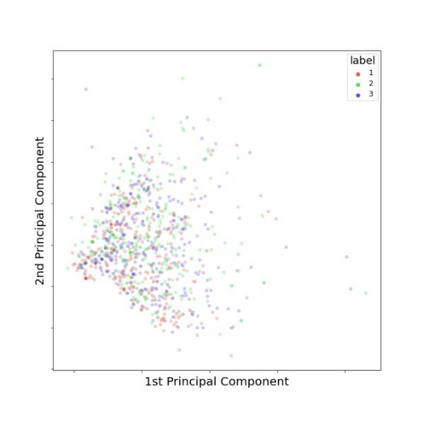
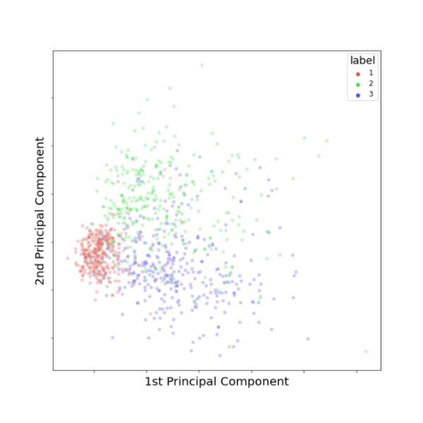
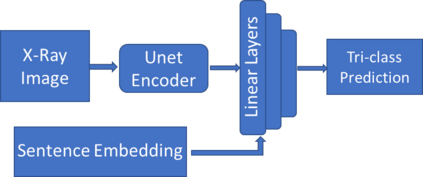
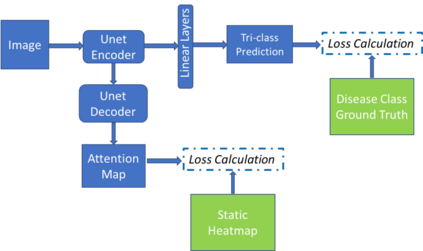
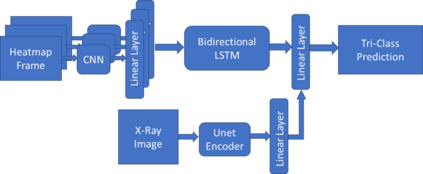
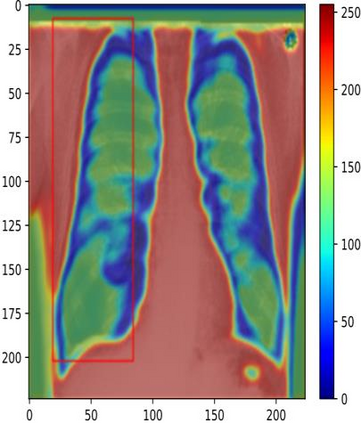
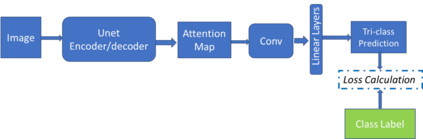
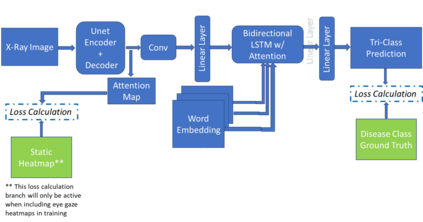
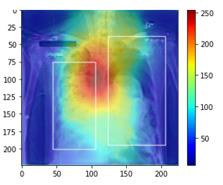
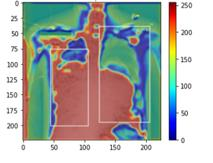
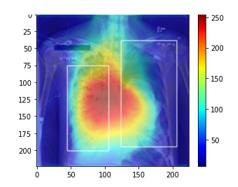
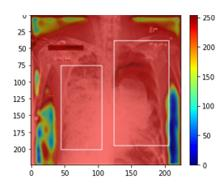
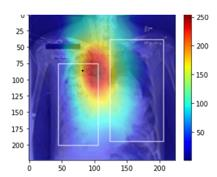
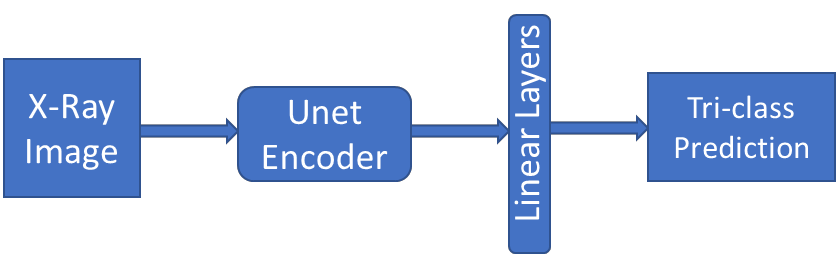
Traditional datasets for the radiological diagnosis tend to only provide the radiology image alongside the radiology report. However, radiology reading as performed by radiologists is a complex process, and information such as the radiologist's eye-fixations over the course of the reading has the potential to be an invaluable data source to learn from. Nonetheless, the collection of such data is expensive and time-consuming. This leads to the question of whether such data is worth the investment to collect. This paper utilizes the recently published Eye-Gaze dataset to perform an exhaustive study on the impact on performance and explainability of deep learning (DL) classification in the face of varying levels of input features, namely: radiology images, radiology report text, and radiologist eye-gaze data. We find that the best classification performance of X-ray images is achieved with a combination of radiology report free-text and radiology image, with the eye-gaze data providing no performance boost. Nonetheless, eye-gaze data serving as secondary ground truth alongside the class label results in highly explainable models that generate better attention maps compared to models trained to do classification and attention map generation without eye-gaze data.
翻译:放射诊断的传统数据集往往只提供放射学图象以及放射学报告,然而,放射学家进行的放射学阅读是一个复杂的过程,放射学家在阅读过程中的眼部固定学等信息有可能成为从中学习的宝贵数据来源,然而,这些数据的收集费用昂贵,耗时费时,由此产生了这些数据是否值得投资收集的问题。本文利用最近出版的眼-伽泽数据集,对在不同的投入特征,即:放射学图像、放射学报告文本和放射学家眼部凝胶数据,对深度学习(DL)分类的性能和可解释性的影响进行详尽的研究。我们发现,X射线图像的最佳分类性能是结合放射学报告自由文本和放射学图像,眼-凝胶数据没有提供性能推动。但是,眼-gaze数据与分类模型相比,在高清晰度标签中产生更好的关注度地图,而没有经过训练的地图生成数据则没有进行分类和注意。