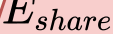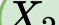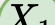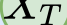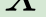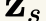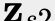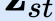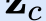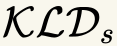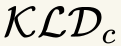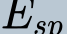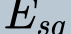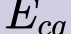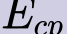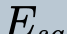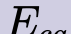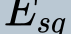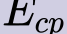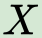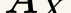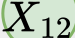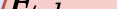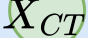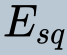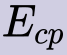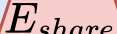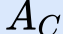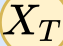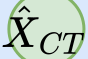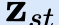In this paper, we propose a novel unsupervised text-to-speech (UTTS) framework which does not require text-audio pairs for the TTS acoustic modeling (AM). UTTS is a multi-speaker speech synthesizer developed from the perspective of disentangled speech representation learning. The framework offers a flexible choice of a speaker's duration model, timbre feature (identity) and content for TTS inference. We leverage recent advancements in self-supervised speech representation learning as well as speech synthesis front-end techniques for the system development. Specifically, we utilize a lexicon to map input text to the phoneme sequence, which is expanded to the frame-level forced alignment (FA) with a speaker-dependent duration model. Then, we develop an alignment mapping module that converts the FA to the unsupervised alignment (UA). Finally, a Conditional Disentangled Sequential Variational Auto-encoder (C-DSVAE), serving as the self-supervised TTS AM, takes the predicted UA and a target speaker embedding to generate the mel spectrogram, which is ultimately converted to waveform with a neural vocoder. We show how our method enables speech synthesis without using a paired TTS corpus. Experiments demonstrate that UTTS can synthesize speech of high naturalness and intelligibility measured by human and objective evaluations.
翻译:在本文中,我们提出一个新的不受监督的文本到语音(UTTS)框架,它不需要TTS声学模型(AM)的文本-音频配对。 UTTS是一个多语语音合成器,是从分解的语音代表学习角度开发的。这个框架为TTS推理提供了一个灵活的选择演讲人的时间长度模型、字边特征(特征)和内容。我们利用了在自我监督的语音演示学习以及系统开发的语音合成前端技术方面的最新进展。具体地说,我们利用一个词汇来将输入文本映射到语音序列序列的文字,该词将扩展至基级强制对齐(FA),并使用一个取决于演讲人的发言时间模型。然后,我们开发了一个校正绘图模块,将FAFA转换为不受监督的校正校正校正(UA)。 最后,一个调调调调调调调调调调调调自控的自动调调音频的自动编码(C-DSVAE),作为自我监督的 TTSAM, 将预测的UA值和目标图像转换成一个不由我们测量的图像。