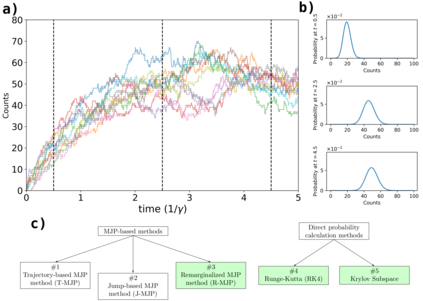
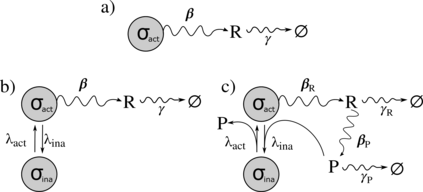
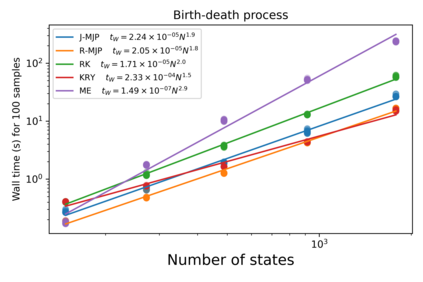
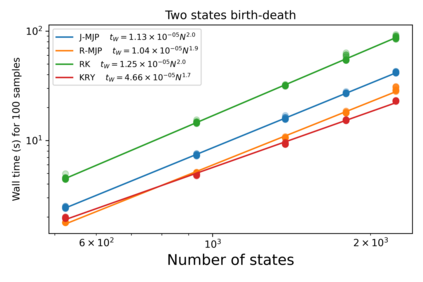
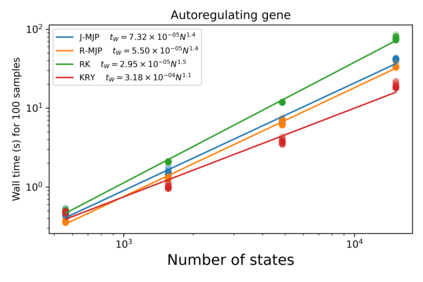
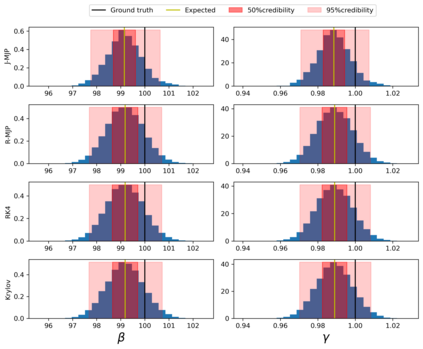
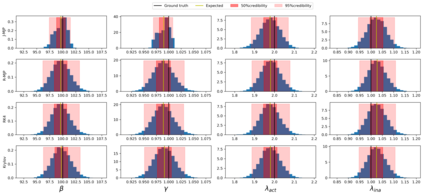
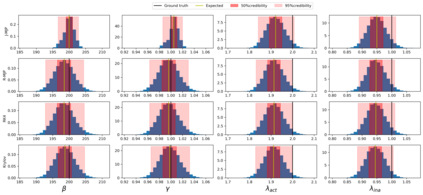
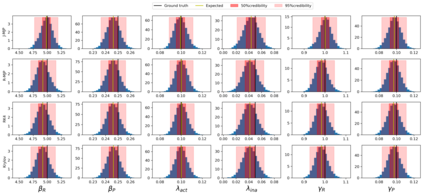
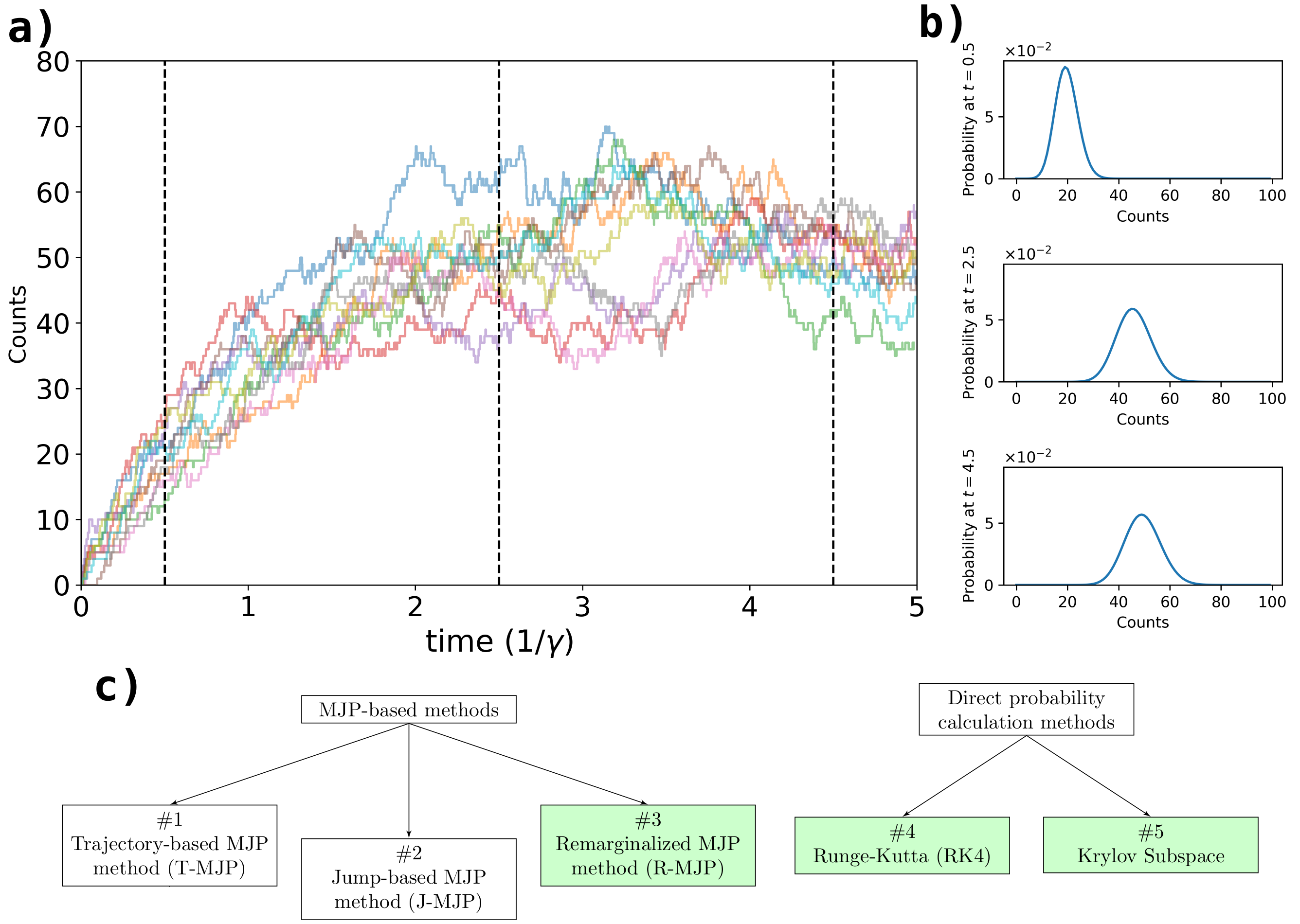
Exact methods for exponentiation of matrices of dimension $N$ can be computationally expensive in terms of execution time ($N^{3}$) and memory requirements ($N^{2}$) not to mention numerical precision issues. A type of matrix often exponentiated in the sciences is the rate matrix. Here we explore five methods to exponentiate rate matrices some of which apply even more broadly to other matrix types. Three of the methods leverage a mathematical analogy between computing matrix elements of a matrix exponential and computing transition probabilities of a dynamical processes (technically a Markov jump process, MJP, typically simulated using Gillespie). In doing so, we identify a novel MJP-based method relying on restricting the number of "trajectory" jumps based on the magnitude of the matrix elements with favorable computational scaling. We then discuss this method's downstream implications on mixing properties of Monte Carlo posterior samplers. We also benchmark two other methods of matrix exponentiation valid for any matrix (beyond rate matrices and, more generally, positive definite matrices) related to solving differential equations: Runge-Kutta integrators and Krylov subspace methods. Under conditions where both the largest matrix element and the number of non-vanishing elements scale linearly with $N$ -- reasonable conditions for rate matrices often exponentiated -- computational time scaling with the most competitive methods (Krylov and one of the MJP-based methods) reduces to $N^2$ with total memory requirements of $N$.
翻译:暂无翻译