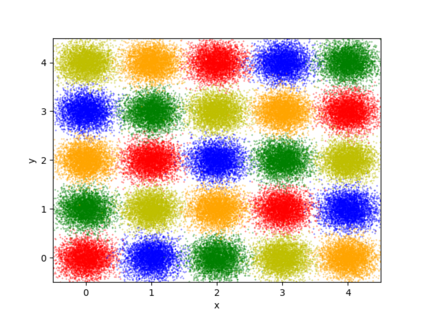
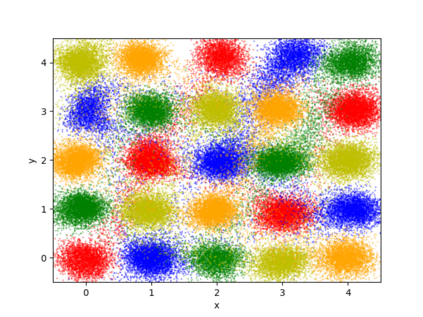
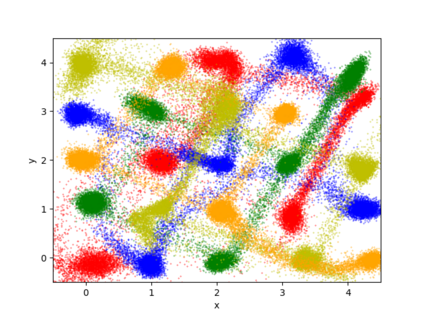
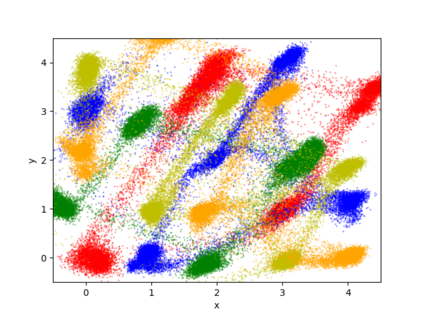
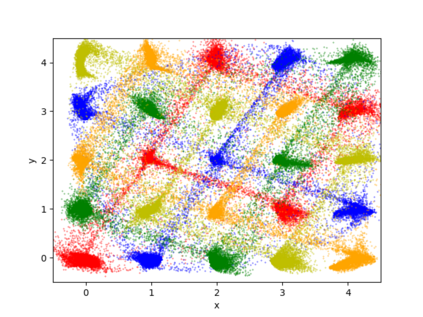
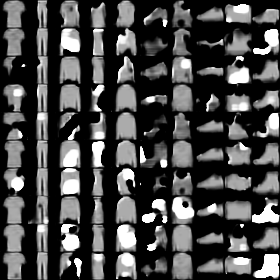
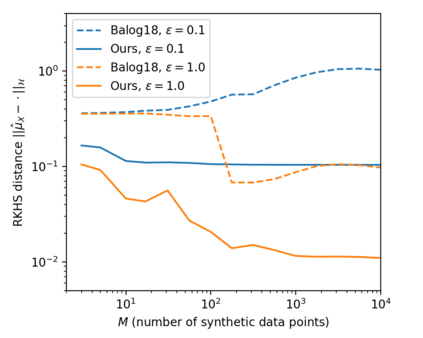
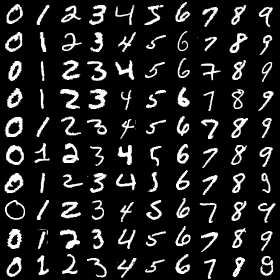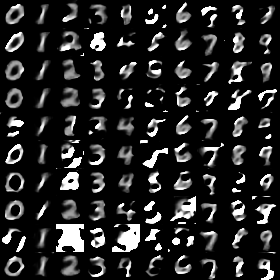We propose a differentially private data generation paradigm using random feature representations of kernel mean embeddings when comparing the distribution of true data with that of synthetic data. We exploit the random feature representations for two important benefits. First, we require a minimal privacy cost for training deep generative models. This is because unlike kernel-based distance metrics that require computing the kernel matrix on all pairs of true and synthetic data points, we can detach the data-dependent term from the term solely dependent on synthetic data. Hence, we need to perturb the data-dependent term only once and then use it repeatedly during the generator training. Second, we can obtain an analytic sensitivity of the kernel mean embedding as the random features are norm bounded by construction. This removes the necessity of hyper-parameter search for a clipping norm to handle the unknown sensitivity of a generator network. We provide several variants of our algorithm, differentially-private mean embeddings with random features (DP-MERF) to jointly generate labels and input features for datasets such as heterogeneous tabular data and image data. Our algorithm achieves drastically better privacy-utility trade-offs than existing methods when tested on several datasets.
翻译:在比较真实数据的分布和合成数据的分布时,我们利用随机的随机特征表示内核嵌入,提出使用随机的私人数据生成模式。我们利用随机特征表示,有两个重要好处。我们利用随机特征表示,我们利用两个重要好处。首先,我们要求为培养深基因模型提供最低隐私成本。这是因为,与内核远程测量不同,要求将内核矩阵计算在所有真实和合成数据点的对等数据上,我们可以将数据依赖的术语从完全依赖合成数据的术语中分离出来。因此,我们需要只对数据依赖术语作一次扰动,然后在发电机培训期间反复使用。第二,我们可以对内核嵌意味着嵌入进行分析性敏感度,因为随机特征是受构建规范的。这取消了超光谱搜索的必要性,以便处理发电机网络的未知敏感度。我们提供了多种算法的变式、有随机特性的差别私人平均嵌入(DP-MEF),以便共同生成数据集的标签和输入特征,例如可比较的表格数据和图像数据。我们的算法在对现有数据进行急剧的保密性测试时,实现了更好的数据贸易方法。