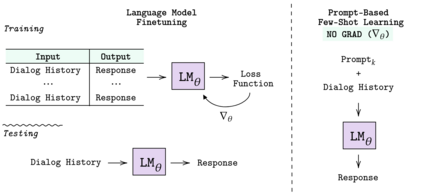
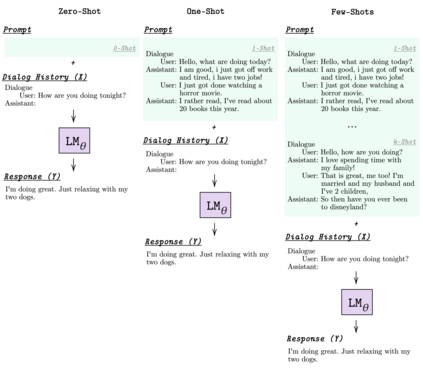
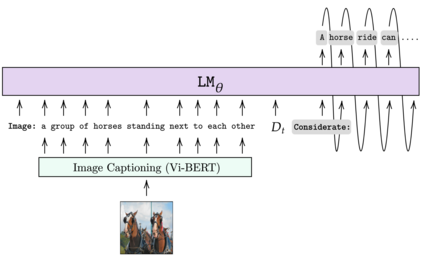
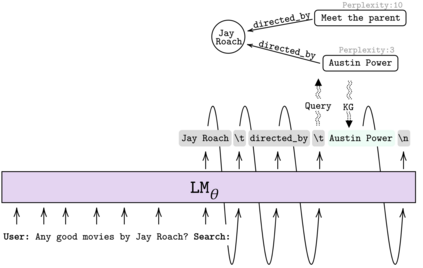
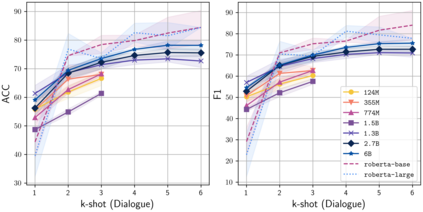
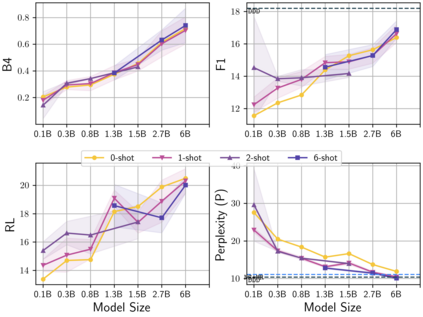
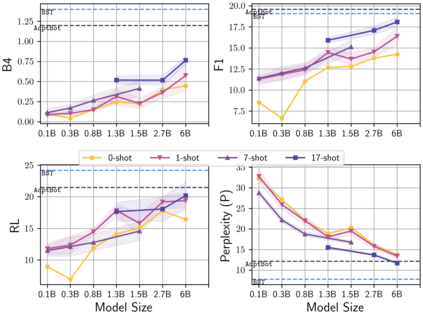
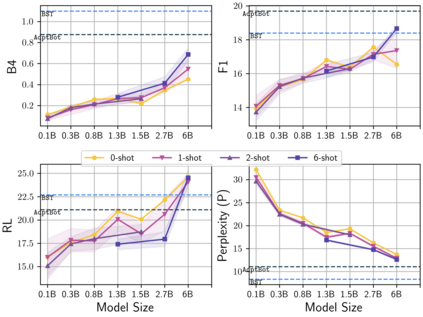
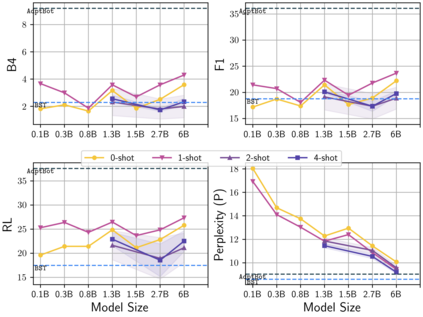
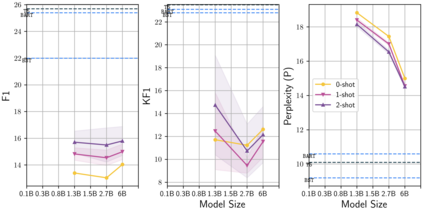
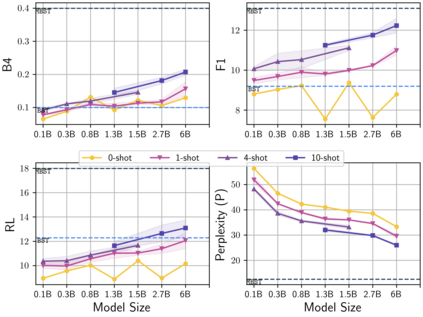
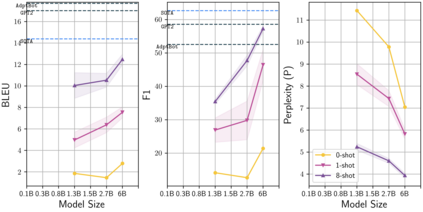
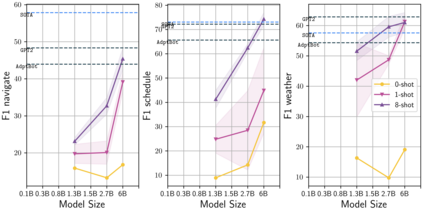
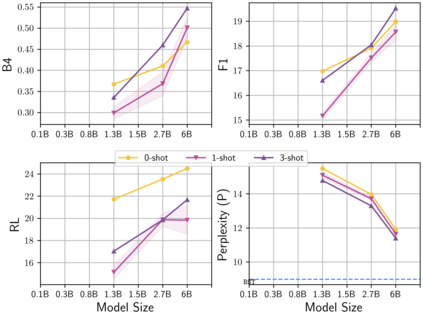
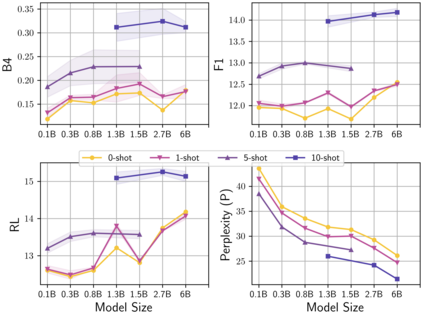
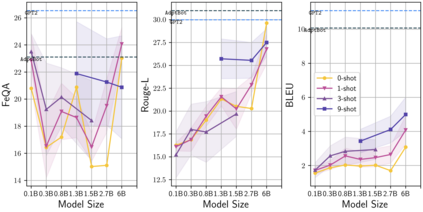
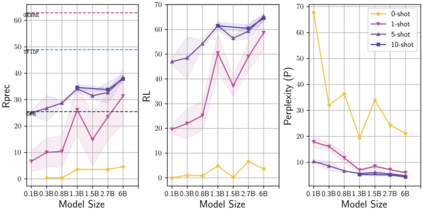
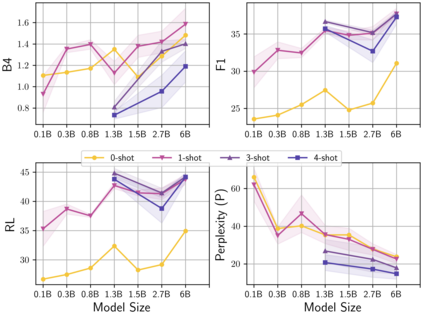
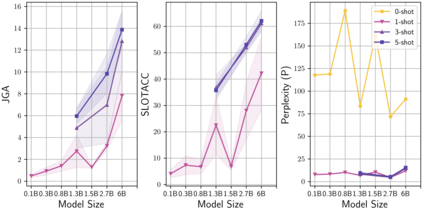
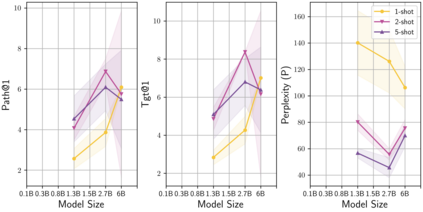
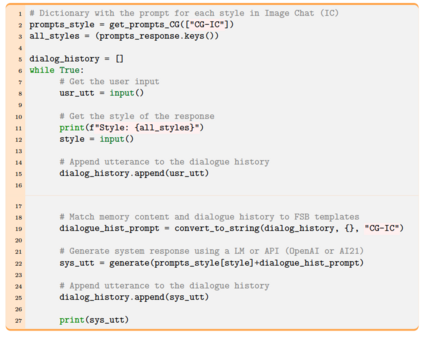
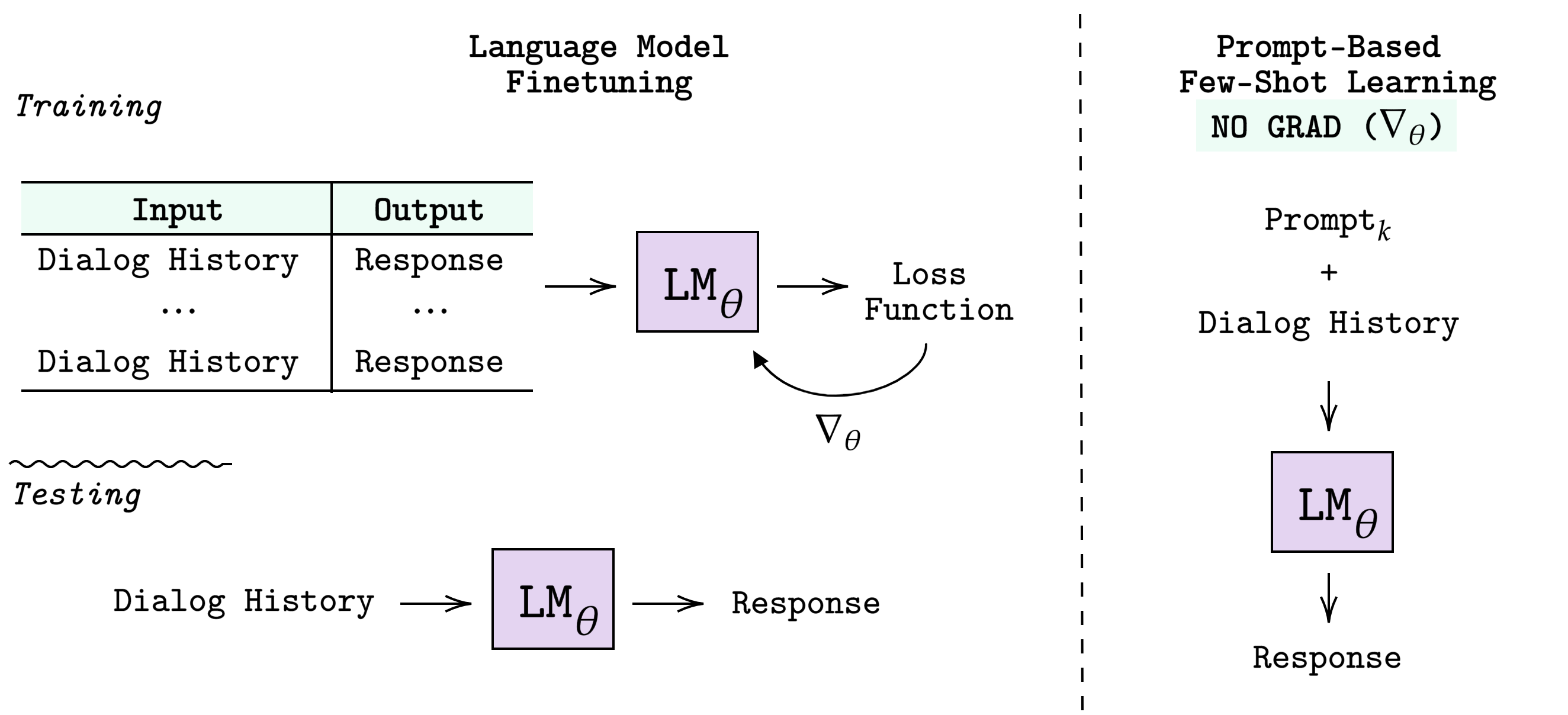
Learning to converse using only a few examples is a great challenge in conversational AI. The current best conversational models, which are either good chit-chatters (e.g., BlenderBot) or goal-oriented systems (e.g., MinTL), are language models (LMs) fine-tuned on large conversational datasets. Training these models is expensive, both in terms of computational resources and time, and it is hard to keep them up to date with new conversational skills. A simple yet unexplored solution is prompt-based few-shot learning (Brown et al. 2020) which does not require gradient-based fine-tuning but instead uses a few examples in the LM context as the only source of learning. In this paper, we explore prompt-based few-shot learning in dialogue tasks. We benchmark LMs of different sizes in nine response generation tasks, which include four knowledge-grounded tasks, a task-oriented generations task, three open-chat tasks, and controlled stylistic generation, and five conversational parsing tasks, which include dialogue state tracking, graph path generation, persona information extraction, document retrieval, and internet query generation. The current largest released LM (GPT-J-6B) using prompt-based few-shot learning, and thus requiring no training, achieves competitive performance to fully trained state-of-the-art models. Moreover, we propose a novel prompt-based few-shot classifier, that also does not require any fine-tuning, to select the most appropriate prompt given a dialogue history. Finally, by combining the power of prompt-based few-shot learning and a Skill Selector, we create an end-to-end chatbot named the Few-Shot Bot (FSB), which automatically selects the most appropriate conversational skill, queries different knowledge bases or the internet, and uses the retrieved knowledge to generate a human-like response, all using only few dialogue examples per skill.
翻译:仅用几个例子学习对口,这是对话AI中的一大挑战。当前最好的对话模式是语言模式(LMS),在大型对话数据集上进行微调。这些模式在计算资源和时间方面费用昂贵,很难跟上新的对话技能。一个简单但尚未探索的解决方案是基于快速的少镜头学习(Brown et al. 2020),这些模式不需要基于梯度的微调调整,而是在LM背景下使用几个实例作为唯一的学习来源。在本文中,我们探索在大型对话数据集上精细调整的语言模式(LMS),在计算资源和时间方面,这些模型的大小不同,包括四个基于知识的任务,基于任务的代际任务,三个基于公开的聊天任务,以及所有FS-直线生成,以及五个对口任务,这五个任务包括:通过快速的跟踪、图表-电路调, 也不需要自动的Sliver-Sliver 数据,因此,我们需要快速的生成的L-G 智能生成数据基础。我们把不同大小的LMRMM