
题目: Leveraging Procedural Generation to Benchmark Reinforcement Learning
摘要:
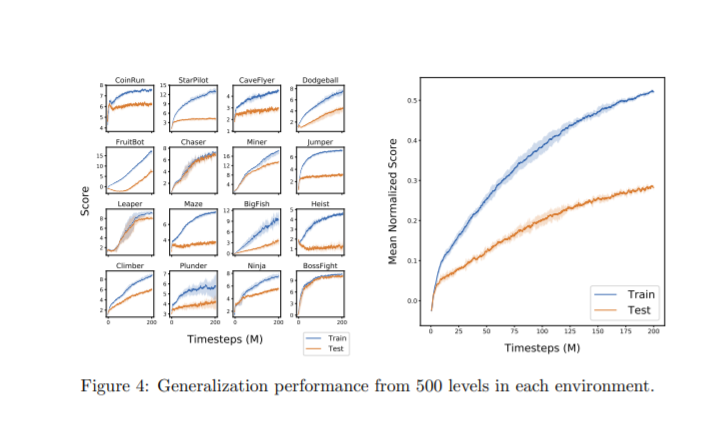
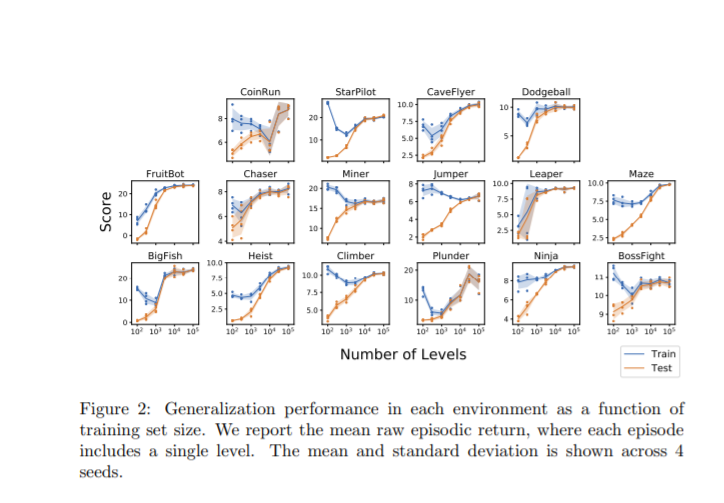
在这份报告中,介绍了Procgen基准测试,这是一套由16个程序生成的类似游戏的环境,旨在对样本效率和增强学习中的泛化进行基准测试。我们相信社区将从高质量的培训环境中受益,我们提供了使用这个基准的详细实验协议。并且以经验证明,不同的环境分布对于充分培训和评估RL代理是至关重要的,从而激发了过程内容生成的广泛使用。然后,我们使用这个基准来研究缩放模型大小的影响,发现更大的模型显著地提高了样本效率和泛化。
个人简介:
Karl Cobbe目前是OpenAI的一名研究科学家。2014年,他以优异的成绩获得了斯坦福大学计算机科学学士学位。他最初加入OpenAI时是一名研究员,在约翰•舒尔曼(John Schulman)的指导下工作。他的研究主要集中在深度强化学习中的泛化和迁移。Karl对利用过程生成来创建不同的训练环境特别感兴趣,以便更好地研究当前算法的局限性和导致过拟合的因素。
成为VIP会员查看完整内容



相关内容

专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
33+阅读 · 2019年12月13日
Arxiv
4+阅读 · 2017年10月26日




相关VIP内容
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
33+阅读 · 2019年12月13日
相关资讯
相关论文
Arxiv
4+阅读 · 2017年10月26日