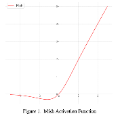
Neural networks are universal function approximators which are known to generalize well despite being dramatically overparameterized. We study this phenomenon from the point of view of the spectral bias of neural networks. Our contributions are two-fold. First, we provide a theoretical explanation for the spectral bias of ReLU neural networks by leveraging connections with the theory of finite element methods. Second, based upon this theory we predict that switching the activation function to a piecewise linear B-spline, namely the Hat function, will remove this spectral bias, which we verify empirically in a variety of settings. Our empirical studies also show that neural networks with the Hat activation function are trained significantly faster using stochastic gradient descent and ADAM. Combined with previous work showing that the Hat activation function also improves generalization accuracy on image classification tasks, this indicates that using the Hat activation provides significant advantages over the ReLU on certain problems.
翻译:神经网络是通用功能近似器,尽管其光度明显过强,但众所周知,它们非常普遍。我们从神经网络的光谱偏差的角度来研究这一现象。我们的贡献是双重的。首先,我们通过利用有限元素方法理论的连接,从理论上解释ReLU神经网络的光谱偏差。第二,根据这一理论,我们预测,将激活功能转换成单线线线B-线,即Hat功能,将消除这种光谱偏差,我们在各种环境中以经验方式核查这些偏差。我们的经验研究还表明,使用光线梯度梯度下移和ADAM对带有Hat激活功能的神经网络进行培训的速度要快得多。加上以往的工作表明,Hat激活功能也提高了图像分类任务的一般精确性,这表明,使用Hat激活在一些问题上比ReLU具有很大的优势。