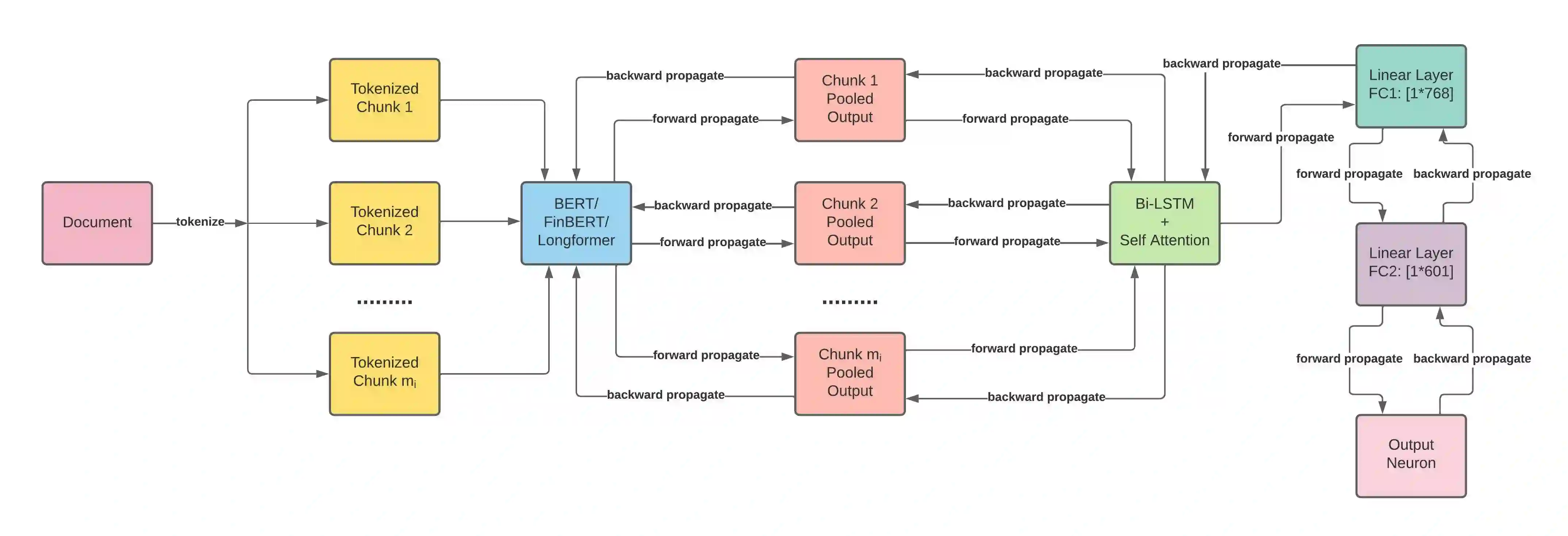
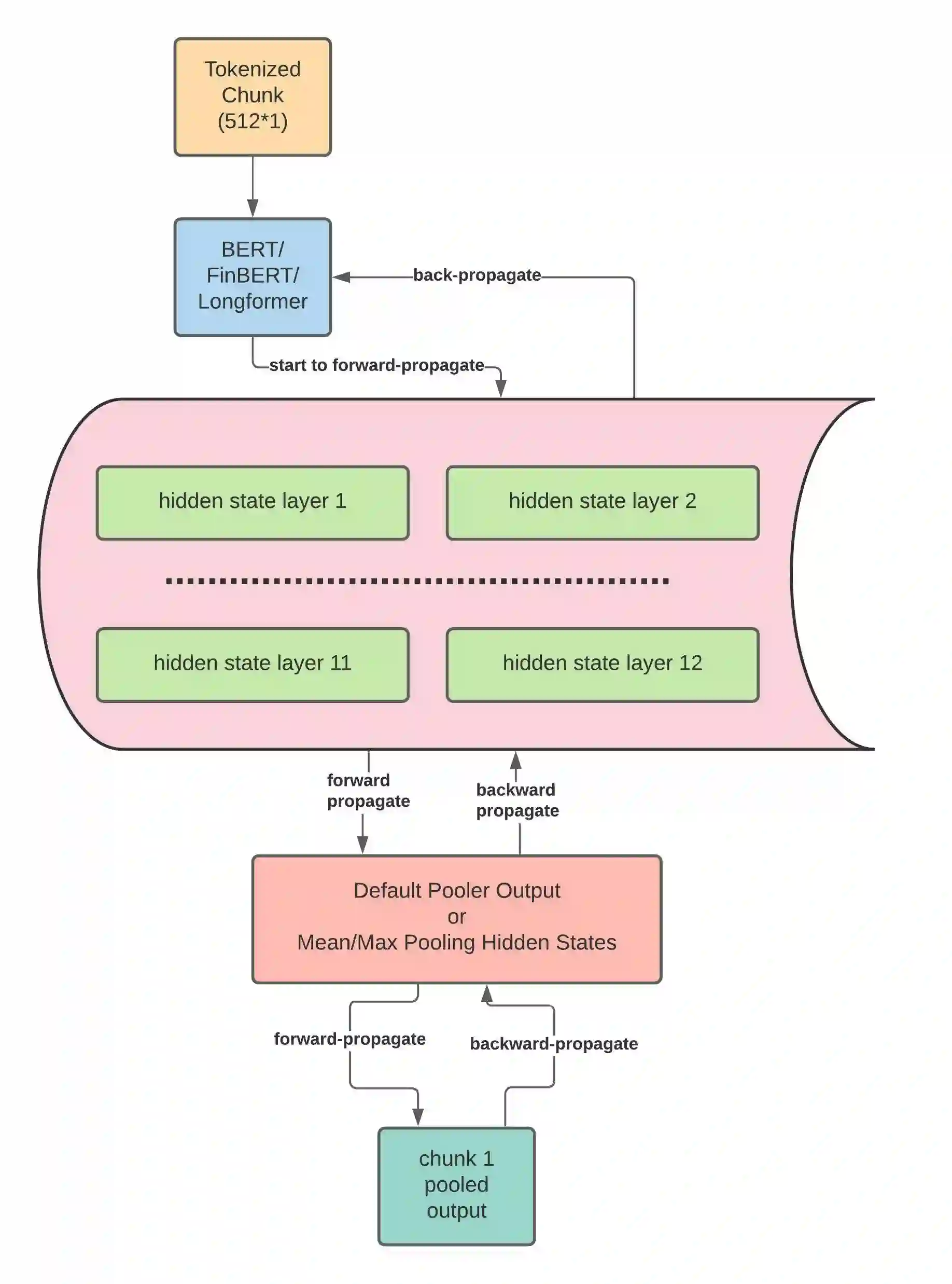
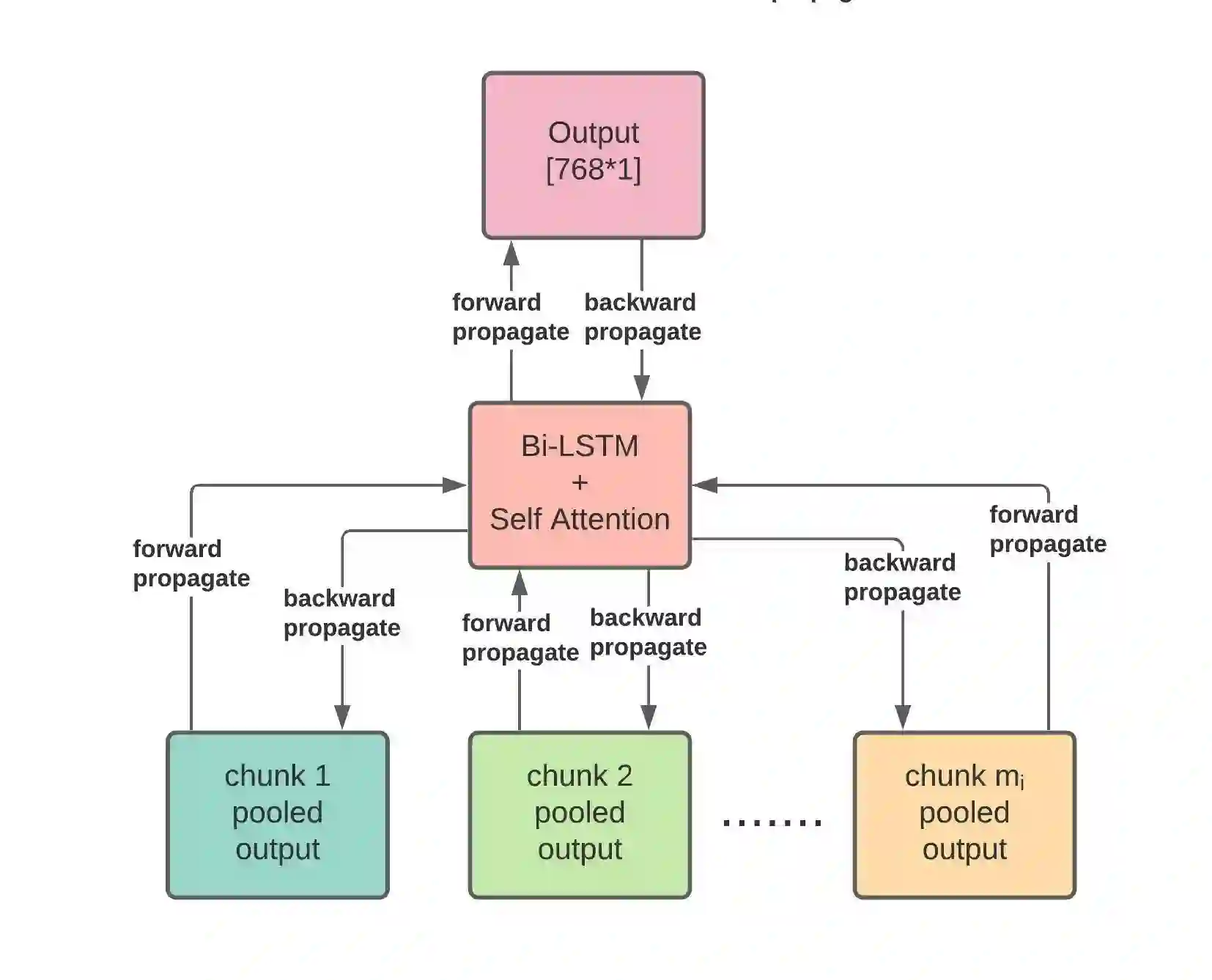
Unstructured data, especially text, continues to grow rapidly in various domains. In particular, in the financial sphere, there is a wealth of accumulated unstructured financial data, such as the textual disclosure documents that companies submit on a regular basis to regulatory agencies, such as the Securities and Exchange Commission (SEC). These documents are typically very long and tend to contain valuable soft information about a company's performance. It is therefore of great interest to learn predictive models from these long textual documents, especially for forecasting numerical key performance indicators (KPIs). Whereas there has been a great progress in pre-trained language models (LMs) that learn from tremendously large corpora of textual data, they still struggle in terms of effective representations for long documents. Our work fills this critical need, namely how to develop better models to extract useful information from long textual documents and learn effective features that can leverage the soft financial and risk information for text regression (prediction) tasks. In this paper, we propose and implement a deep learning framework that splits long documents into chunks and utilizes pre-trained LMs to process and aggregate the chunks into vector representations, followed by self-attention to extract valuable document-level features. We evaluate our model on a collection of 10-K public disclosure reports from US banks, and another dataset of reports submitted by US companies. Overall, our framework outperforms strong baseline methods for textual modeling as well as a baseline regression model using only numerical data. Our work provides better insights into how utilizing pre-trained domain-specific and fine-tuned long-input LMs in representing long documents can improve the quality of representation of textual data, and therefore, help in improving predictive analyses.
翻译:没有结构化的数据,特别是文本,在不同领域继续迅速增长。特别是,在金融领域,积累了大量没有结构化的财务数据,例如公司定期向证券交易委员会(SEC)等监管机构提交的文本披露文件。这些文件通常非常长,往往包含关于公司业绩的宝贵软信息。因此,从这些长长的文本文件中学习预测模型,特别是用于预测数字关键业绩指标(KPIs)非常有意义。在预先培训的语言模型(LMS)中,从大量文本数据中学习了大量没有结构化的金融数据,例如公司定期向证券交易委员会(SEC)等监管机构(SEC)提交文本披露文件。这些文件通常非常长,往往包含关于公司业绩的宝贵软财务和风险信息。在本文中,我们建议和实施一个深度学习框架,将长期文件分为块,利用经过培训的LMS(LM)模型来更好地处理和汇总长期的正版文件。它们仍然在有效展示长期文件方面挣扎。我们的工作填补了这一关键的需求,即如何开发更好的模型,从长的文本文件中提取有用的信息和风险信息,然后又用一个有价值的数据披露的美国的文件。