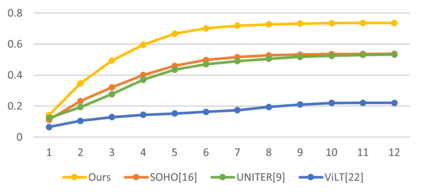
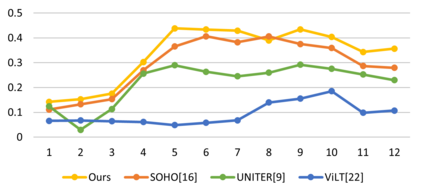
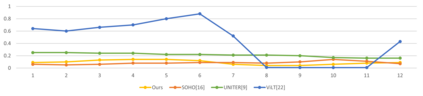
Vision-Language Pre-training (VLP) aims to learn multi-modal representations from image-text pairs and serves for downstream vision-language tasks in a fine-tuning fashion. The dominant VLP models adopt a CNN-Transformer architecture, which embeds images with a CNN, and then aligns images and text with a Transformer. Visual relationship between visual contents plays an important role in image understanding and is the basic for inter-modal alignment learning. However, CNNs have limitations in visual relation learning due to local receptive field's weakness in modeling long-range dependencies. Thus the two objectives of learning visual relation and inter-modal alignment are encapsulated in the same Transformer network. Such design might restrict the inter-modal alignment learning in the Transformer by ignoring the specialized characteristic of each objective. To tackle this, we propose a fully Transformer visual embedding for VLP to better learn visual relation and further promote inter-modal alignment. Specifically, we propose a metric named Inter-Modality Flow (IMF) to measure the interaction between vision and language modalities (i.e., inter-modality). We also design a novel masking optimization mechanism named Masked Feature Regression (MFR) in Transformer to further promote the inter-modality learning. To the best of our knowledge, this is the first study to explore the benefit of Transformer for visual feature learning in VLP. We verify our method on a wide range of vision-language tasks, including Image-Text Retrieval, Visual Question Answering (VQA), Visual Entailment and Visual Reasoning. Our approach not only outperforms the state-of-the-art VLP performance, but also shows benefits on the IMF metric.
翻译:培训前的视觉语言(VLP)旨在从图像-文字配对中学习多式表达方式,并以微调的方式为下游的视觉语言任务服务。 占主导地位的 VLP 模型采用CNN- Transfer 结构,该结构将图像嵌入CNN- Transfer,然后将图像和文字与变异器相匹配。 视觉内容之间的视觉关系在图像理解中起着重要作用,是跨模式调整学习的基础。 然而,CNN在视觉关系学习方面存在局限性,原因是当地接受的场在模拟远程依赖性方面的弱点。 因此,学习视觉关系和跨模式的图像语言调整的两个目标被包含在同一变异器网络中。 这样的设计可能会通过忽略每个目标的专门性能限制变异器的跨模式调整学习。 为了解决这个问题,我们提议为VLP提供完全变异式的视觉嵌入,以更好地学习视觉关系,进一步促进模式的校正的校正的校正性调整。 我们首先提议用名为VRV-L Fal-L Fal-Real-Redal-Refal Exal-al-al-IGal-al-IL-IL-IL-IL-IL-Real-IL-IL-S-IL-IL-ID-ID-I-I-I-I-I-I-S-I-I-I-I-I-I-I-I-S-I-I-I-I-I-S-S-I-S-S-I-S-S-S-I-I-ID-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-