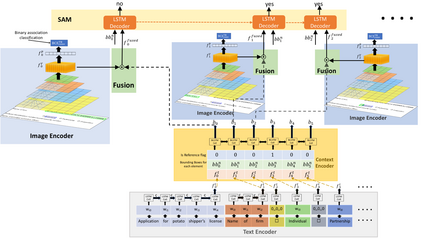
Document structure extraction has been a widely researched area for decades. Recent work in this direction has been deep learning-based, mostly focusing on extracting structure using fully convolution NN through semantic segmentation. In this work, we present a novel multi-modal approach for form structure extraction. Given simple elements such as textruns and widgets, we extract higher-order structures such as TextBlocks, Text Fields, Choice Fields, and Choice Groups, which are essential for information collection in forms. To achieve this, we obtain a local image patch around each low-level element (reference) by identifying candidate elements closest to it. We process textual and spatial representation of candidates sequentially through a BiLSTM to obtain context-aware representations and fuse them with image patch features obtained by processing it through a CNN. Subsequently, the sequential decoder takes this fused feature vector to predict the association type between reference and candidates. These predicted associations are utilized to determine larger structures through connected components analysis. Experimental results show the effectiveness of our approach achieving a recall of 90.29%, 73.80%, 83.12%, and 52.72% for the above structures, respectively, outperforming semantic segmentation baselines significantly. We show the efficacy of our method through ablations, comparing it against using individual modalities. We also introduce our new rich human-annotated Forms Dataset.
翻译:几十年来,文件结构的提取一直是广泛研究的领域。最近在这方面的工作一直是以深层次学习为基础,主要侧重于利用完全进化的NNN通过语义分割进行提取结构。在这项工作中,我们提出了一种新颖的多式结构结构提取方法。鉴于文本运行和部件等简单元素,我们提取了像TextBlocks、文本字段、选择字段和选择小组这样的更高级结构,这些结构对于形式的信息收集至关重要。为了实现这一点,我们通过确定最接近于它的候选元素(参考),在每一个低级元素(参考)周围获得一个本地图像补丁。我们通过BILSTM对候选人的文本和空间代表顺序进行处理,以获得符合上下文的表达方式和空间代表,并将它们与通过CNCN处理获得的图像提取的图像补全特性结合起来。随后,顺序解码将这一集成的特性矢量用于预测参考和候选人之间的关联类型。这些预测的组合被用来通过链接分析确定更大的结构。为了实现这一点,我们的方法的有效性在于确定一个90.29 %、73.80%、83.12%和52.722%的方法,我们用新的结构来大大地展示了我们的数据结构的效能,我们通过一个不同的结构。