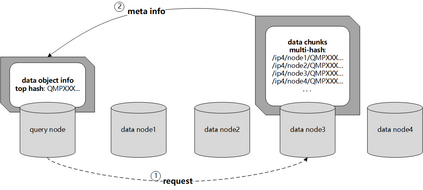
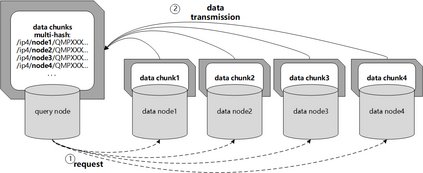
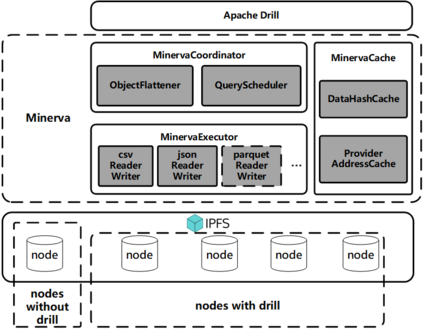
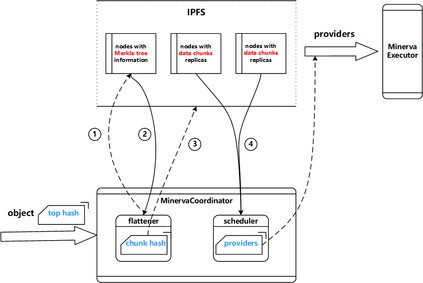
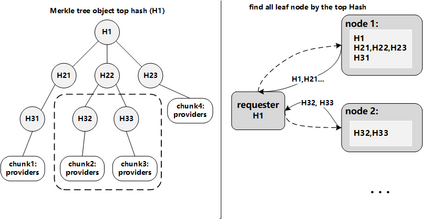
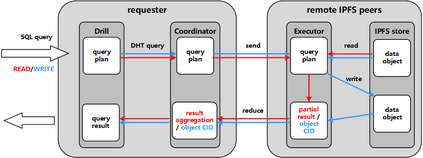
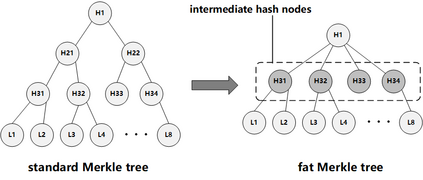
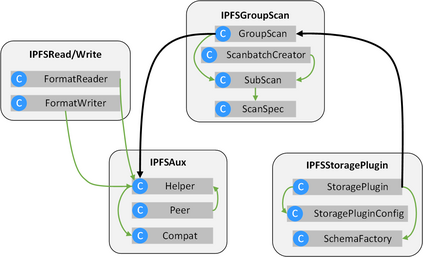
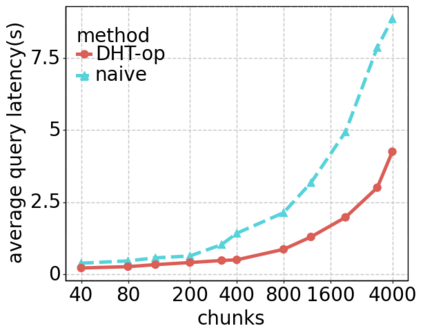
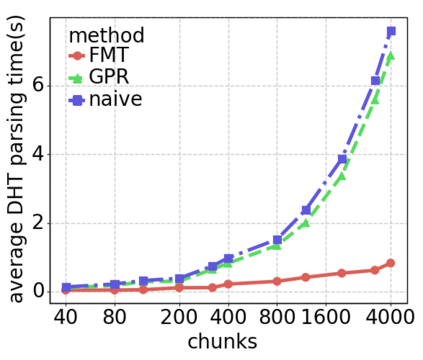
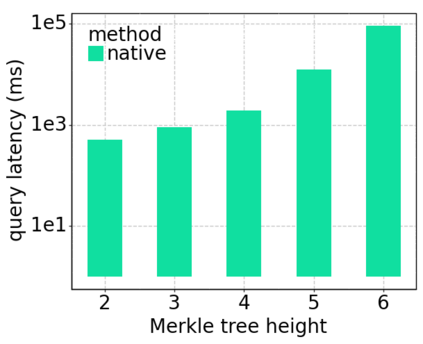
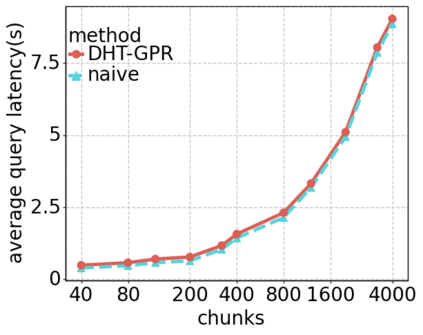
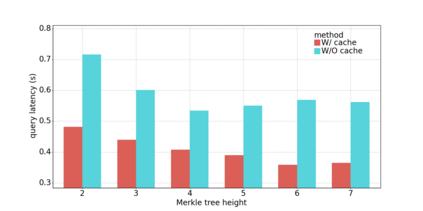
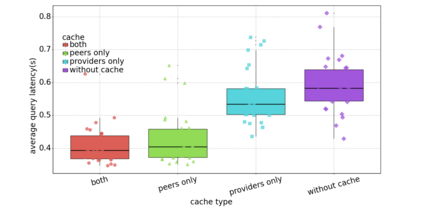
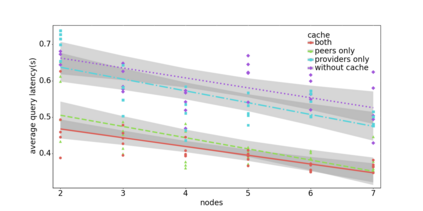
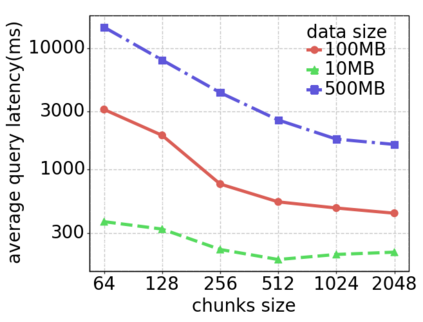
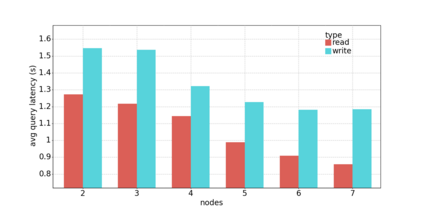
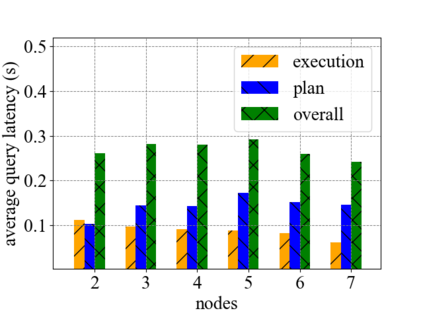
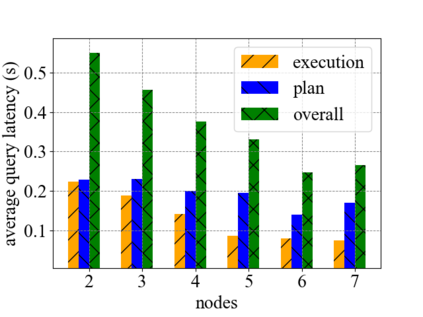
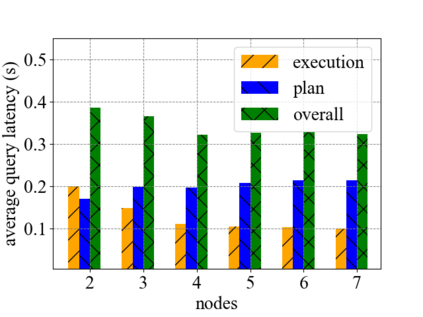
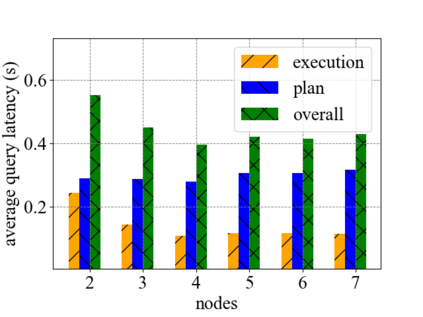
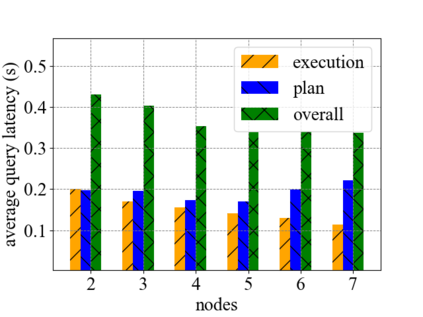
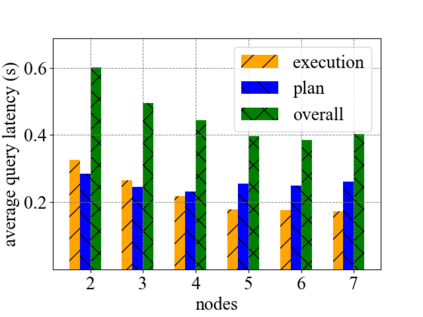
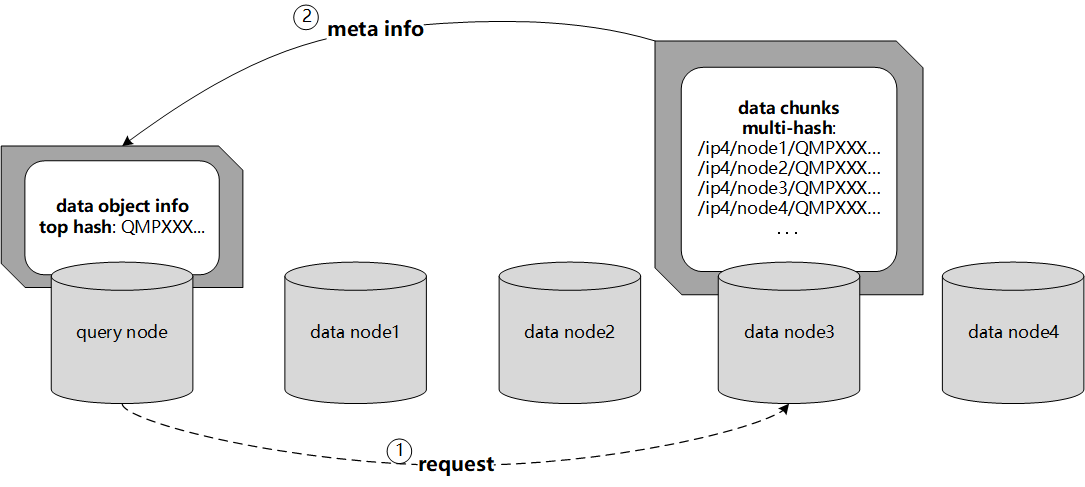
Data silos create barriers in accessing and utilizing data dispersed over networks. Directly sharing data easily suffers from the long downloading time, the single point failure and the untraceable data usage. In this paper, we present Minerva, a peer-to-peer cross-cluster data query system based on InterPlanetary File System (IPFS). Minerva makes use of the distributed Hash table (DHT) lookup to pinpoint the locations that store content chunks. We theoretically model the DHT query delay and introduce the fat Merkle tree structure as well as the DHT caching to reduce it. We design the query plan for read and write operations on top of Apache Drill that enables the collaborative query with decentralized workers. We conduct comprehensive experiments on Minerva, and the results show that Minerva achieves up to $2.08 \times$ query performance acceleration compared to the original IPFS data query, and could complete data analysis queries on the Internet-like environments within an average latency of $0.615$ second. With collaborative query, Minerva could perform up to $1.39 \times$ performance acceleration than centralized query with raw data shipment.
翻译:暂无翻译