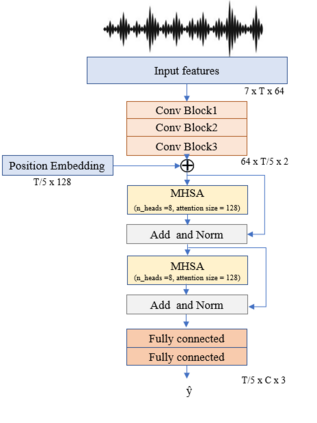
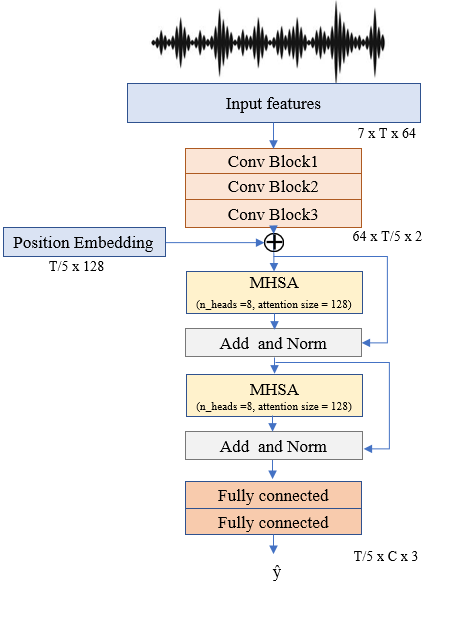
Joint sound event localization and detection (SELD) is an emerging audio signal processing task adding spatial dimensions to acoustic scene analysis and sound event detection. A popular approach to modeling SELD jointly is using convolutional recurrent neural network (CRNN) models, where CNNs learn high-level features from multi-channel audio input and the RNNs learn temporal relationships from these high-level features. However, RNNs have some drawbacks, such as a limited capability to model long temporal dependencies and slow training and inference times due to their sequential processing nature. Recently, a few SELD studies used multi-head self-attention (MHSA), among other innovations in their models. MHSA and the related transformer networks have shown state-of-the-art performance in various domains. While they can model long temporal dependencies, they can also be parallelized efficiently. In this paper, we study in detail the effect of MHSA on the SELD task. Specifically, we examined the effects of replacing the RNN blocks with self-attention layers. We studied the influence of stacking multiple self-attention blocks, using multiple attention heads in each self-attention block, and the effect of position embeddings and layer normalization. Evaluation on the DCASE 2021 SELD (task 3) development data set shows a significant improvement in all employed metrics compared to the baseline CRNN accompanying the task.
翻译:联合声音活动本地化和探测(SELD)是一个新兴的音频信号处理任务,在声学场景分析和声音事件探测中增加了空间维度。最近,一些SELD研究采用多头自省(MHSA)和其他创新模式,对SELD进行联合建模。MHSA和相关变压器网络在不同领域展示了最新水平的性能。虽然它们可以模拟长期的时际依赖性,但它们也可以有效地与这些高水平特征并行。在本文中,我们详细研究MHSA对SELD任务的影响。具体地说,我们研究了用自控层取代RNNE区的影响。最近,一些SELD研究使用了多头自省(MHSA)和其他模型的创新方法。MHSA和相关变压器网络在不同领域展示了最新水平的状态。虽然它们可以模拟长期的时空依赖性关系,但也可以同时进行。我们详细研究MHSA对SA对SL任务的影响。我们研究了用自控层结构取代RNNN(M)的影响。我们研究了多头自控多头自控(MHA)和SEDSEA(SEA)中每个重要的SAL 20级升级的自评分级(SD)的SB级) 的自我定位定位和双级(SD) 20级(SIS级) 的SD级) 的自我定位) 的SD) 。