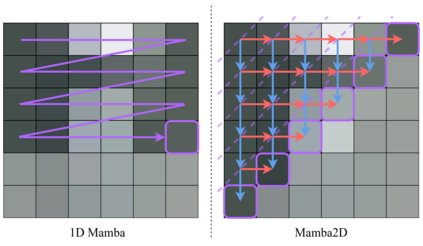
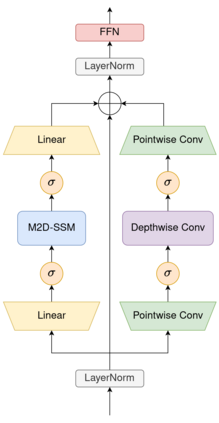
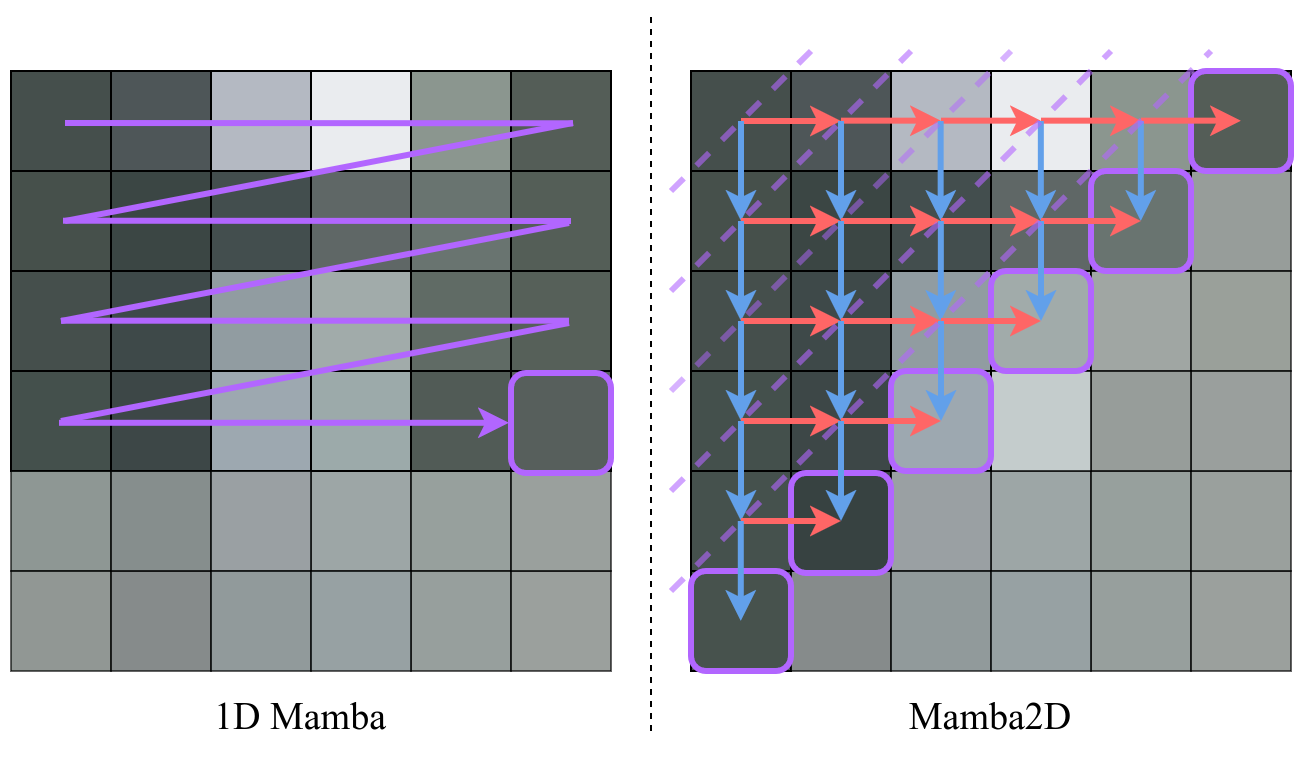
State-Space Models (SSMs) have recently emerged as a powerful and efficient alternative to the long-standing transformer architecture. However, existing SSM conceptualizations retain deeply rooted biases from their roots in natural language processing. This constrains their ability to appropriately model the spatially-dependent characteristics of visual inputs. In this paper, we address these limitations by re-deriving modern selective state-space techniques, starting from a natively multidimensional formulation. Currently, prior works attempt to apply natively 1D SSMs to 2D data (i.e. images) by relying on arbitrary combinations of 1D scan directions to capture spatial dependencies. In contrast, Mamba2D improves upon this with a single 2D scan direction that factors in both dimensions of the input natively, effectively modelling spatial dependencies when constructing hidden states. Mamba2D shows comparable performance to prior adaptations of SSMs for vision tasks, on standard image classification evaluations with the ImageNet-1K dataset.
翻译:暂无翻译