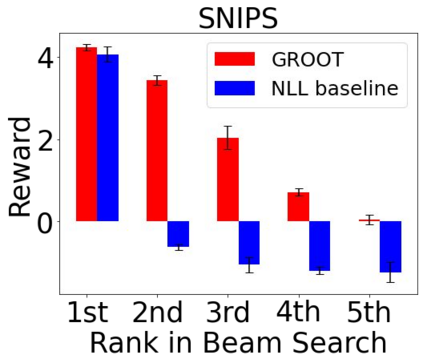
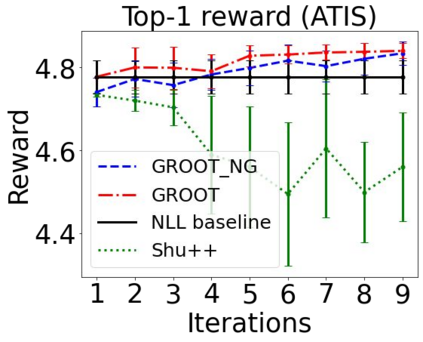
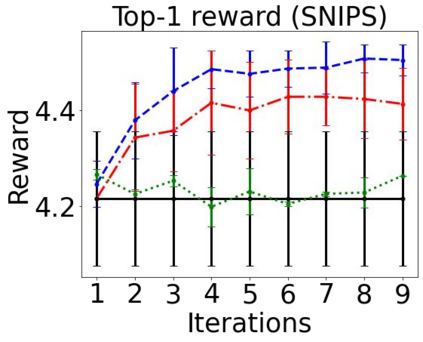
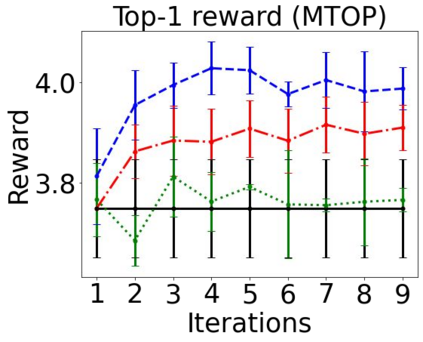
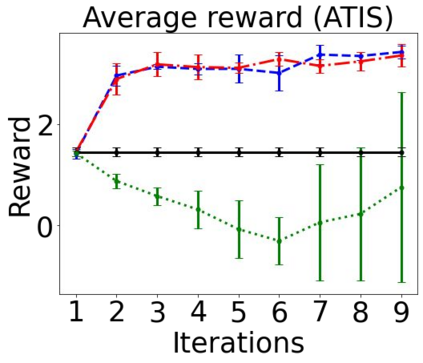
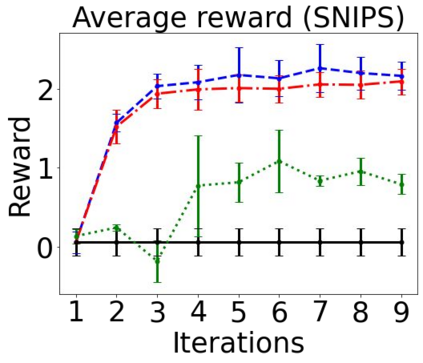
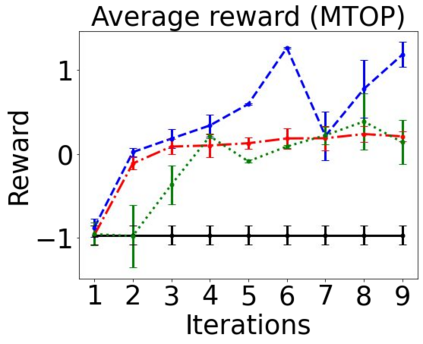
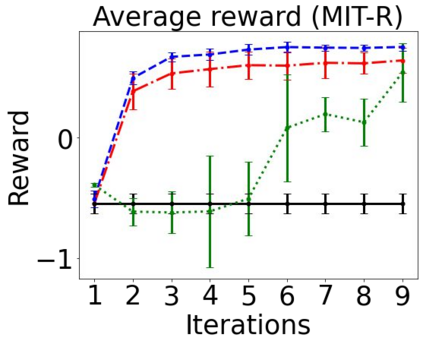
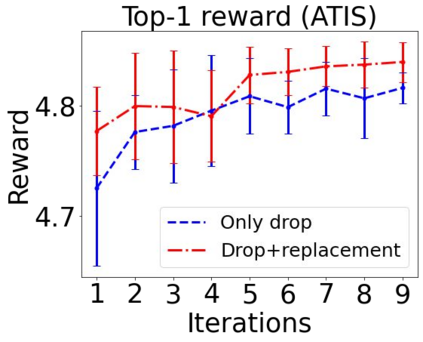
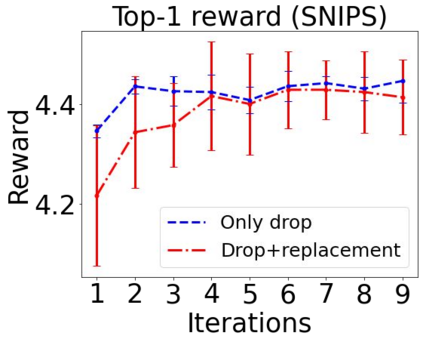
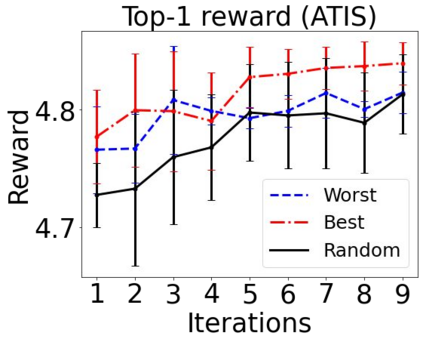
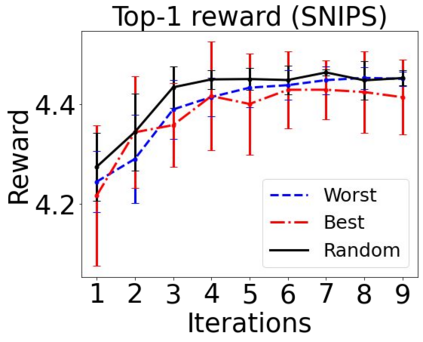
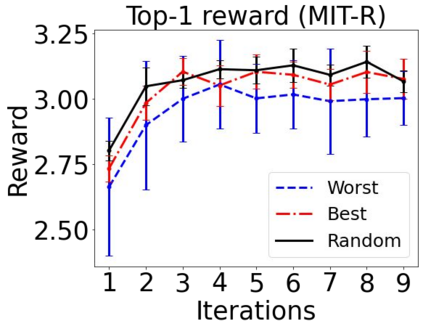
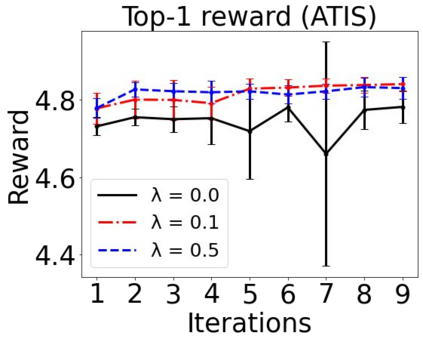
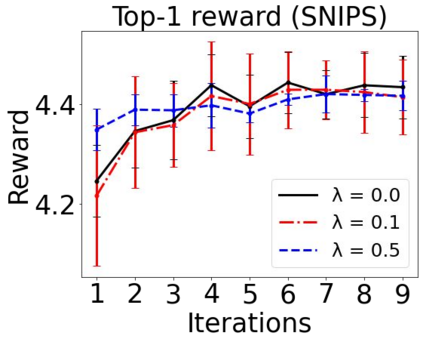
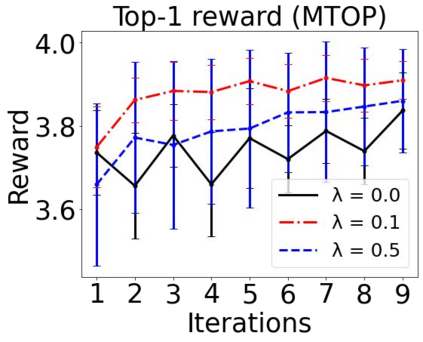
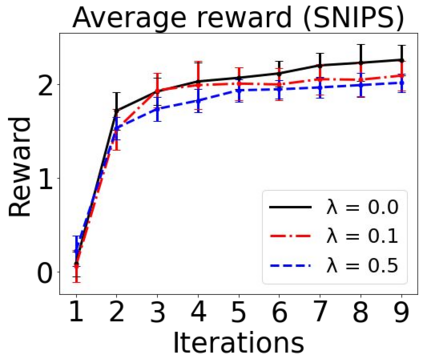
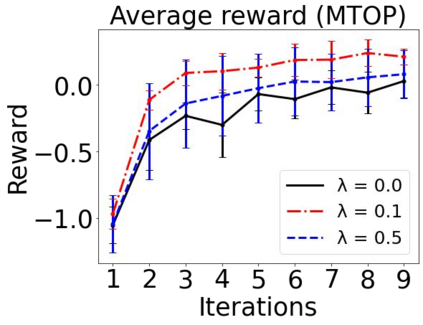
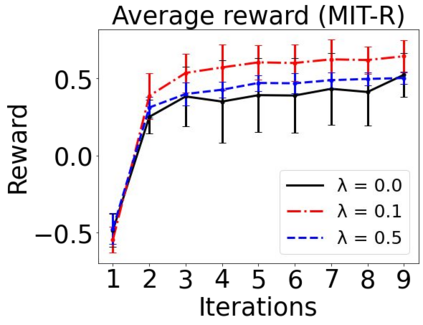
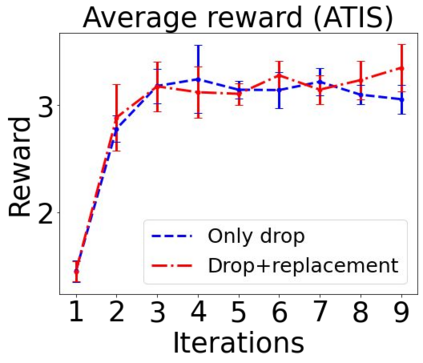
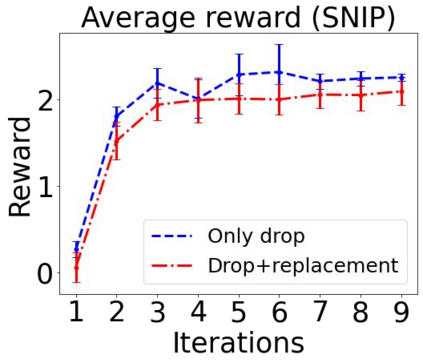
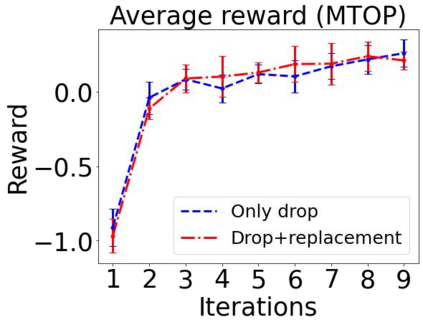
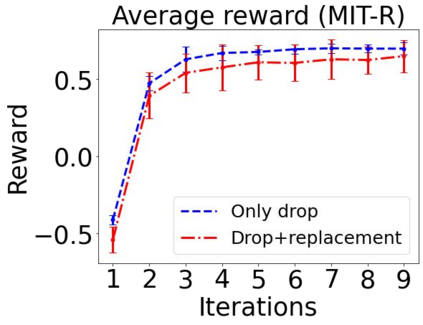
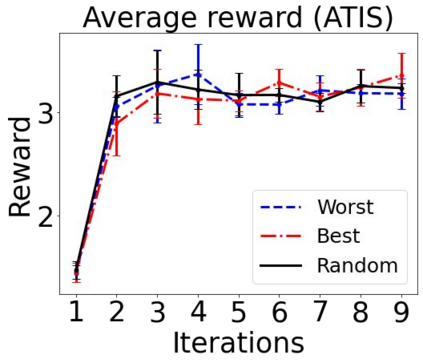
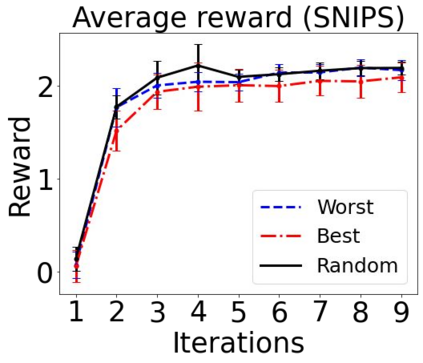
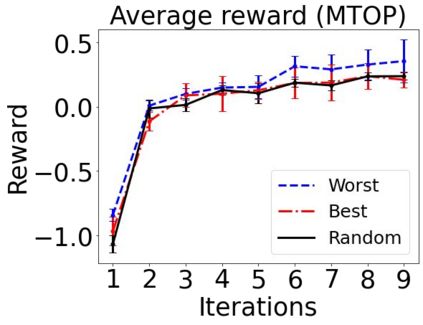
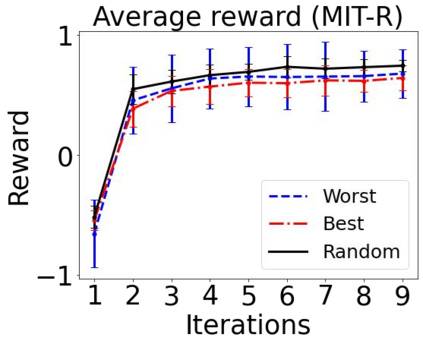
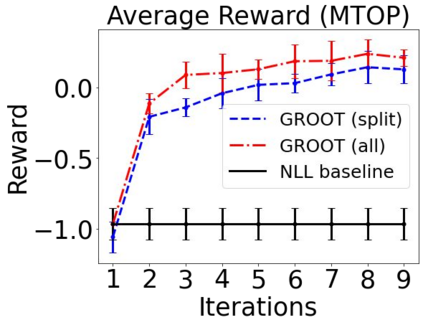
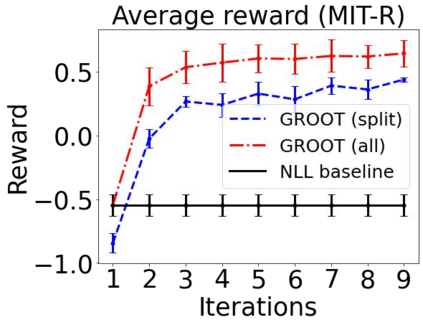
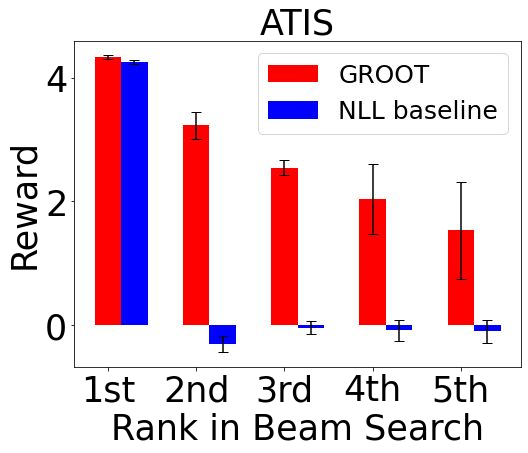
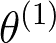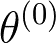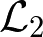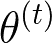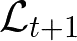Sequential labeling is a fundamental NLP task, forming the backbone of many applications. Supervised learning of Seq2Seq models has shown great success on these problems. However, the training objectives are still significantly disconnected with the metrics and desiderata we care about in practice. For example, a practical sequence tagging application may want to optimize for a certain precision-recall trade-off (of the top-k predictions) which is quite different from the standard objective of maximizing the likelihood of the gold labeled sequence. Thus to bridge this gap, we propose GROOT -- a simple yet effective framework for Generative Reward Optimization Of Text sequences. GROOT works by training a generative sequential labeling model to match the decoder output distribution with that of the (black-box) reward function. Using an iterative training regime, we first generate prediction candidates, then correct errors in them, and finally contrast those candidates (based on their reward values). As demonstrated via extensive experiments on four public benchmarks, GROOT significantly improves all reward metrics. Furthermore, GROOT leads to improvements of the overall decoder distribution as evidenced by the quality gains of the top-$k$ candidates.
翻译:序列标签是一项基本的NLP任务,它构成了许多应用的支柱。监督的Seq2Seqeq模型的学习证明在这些问题上取得了巨大成功。然而,培训目标仍然与我们实际关心的衡量尺度和贬义大相脱节。例如,实用的序列标记应用可能想要优化某种精确-回调权衡(最上方的预测),这与尽可能扩大标注的黄金序列的可能性的标准目标大不相同。为了缩小这一差距,我们建议GROOT -- -- 一个简单而有效的文本序列的生成向上优化框架。GROOT通过培训一个基因化顺序标签模型,将脱coder输出分布与(黑盒)奖励功能相匹配。我们首先利用反复的培训制度,我们首先产生预测候选人,然后纠正其中的错误,最后比较这些候选人(根据他们的奖赏价值)。通过对四项公共基准的广泛试验,GROOT大大改进了所有计量标准。此外,GROOT通过培训,以美元导致提高候选人总体脱coder分布的质量。