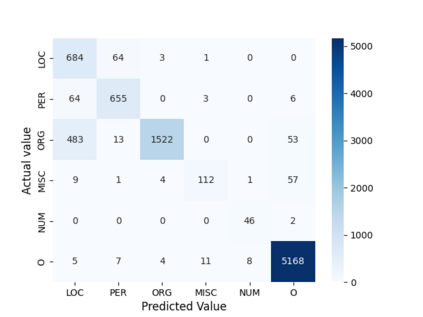
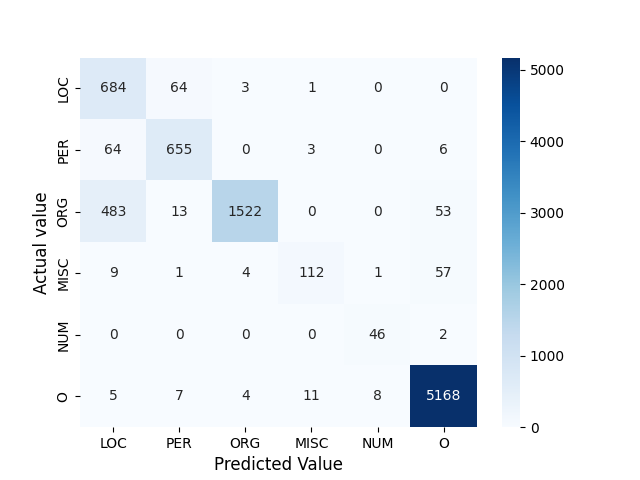
We present the AsNER, a named entity annotation dataset for low resource Assamese language with a baseline Assamese NER model. The dataset contains about 99k tokens comprised of text from the speech of the Prime Minister of India and Assamese play. It also contains person names, location names and addresses. The proposed NER dataset is likely to be a significant resource for deep neural based Assamese language processing. We benchmark the dataset by training NER models and evaluating using state-of-the-art architectures for supervised named entity recognition (NER) such as Fasttext, BERT, XLM-R, FLAIR, MuRIL etc. We implement several baseline approaches with state-of-the-art sequence tagging Bi-LSTM-CRF architecture. The highest F1-score among all baselines achieves an accuracy of 80.69% when using MuRIL as a word embedding method. The annotated dataset and the top performing model are made publicly available.
翻译:我们以亚萨姆语为低资源实体的注解数据集,以亚萨姆语为基准,以阿萨姆语为基准。该数据集包含大约99k个符号,由印度总理讲话和阿萨姆斯游戏的文字组成。该数据集还包含个人姓名、地点名称和地址。拟议的新网数据集很可能是深层神经基础亚萨姆语处理的重要资源。我们通过培训净资源模型和采用最先进的结构来评估数据集,以监督的命名实体识别(NER),如快文本、BERT、XLM-R、FLAIR、MuRIL等。我们实施了几种基线方法,以最先进的顺序标出BILSTM-CRF结构。所有基线中最高的F1核心在使用MuRIL作为单词嵌入方法时达到80.69%的准确率。附加说明的数据集和顶级演算模型公布于众。