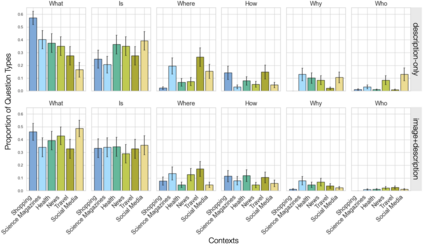
Visual question answering (VQA) has the potential to make the Internet more accessible in an interactive way, allowing people who cannot see images to ask questions about them. However, multiple studies have shown that people who are blind or have low-vision prefer image explanations that incorporate the context in which an image appears, yet current VQA datasets focus on images in isolation. We argue that VQA models will not fully succeed at meeting people's needs unless they take context into account. To further motivate and analyze the distinction between different contexts, we introduce Context-VQA, a VQA dataset that pairs images with contexts, specifically types of websites (e.g., a shopping website). We find that the types of questions vary systematically across contexts. For example, images presented in a travel context garner 2 times more "Where?" questions, and images on social media and news garner 2.8 and 1.8 times more "Who?" questions than the average. We also find that context effects are especially important when participants can't see the image. These results demonstrate that context affects the types of questions asked and that VQA models should be context-sensitive to better meet people's needs, especially in accessibility settings.
翻译:暂无翻译