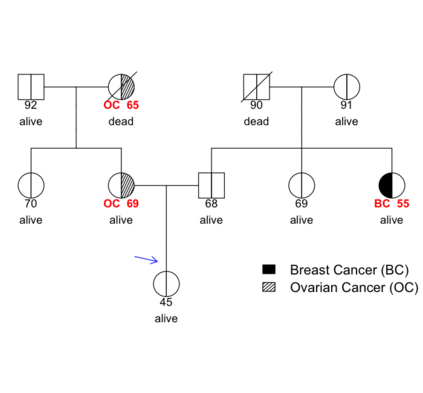
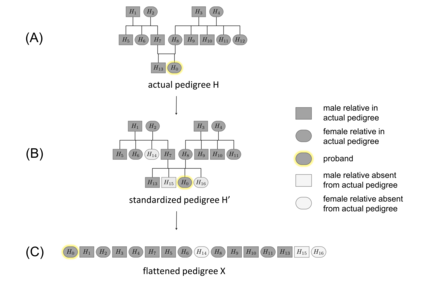
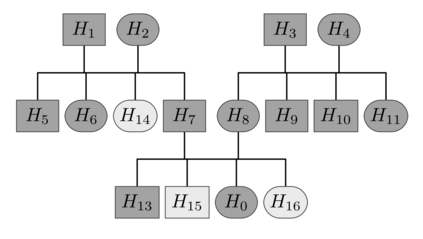
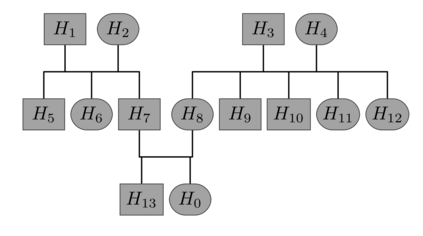
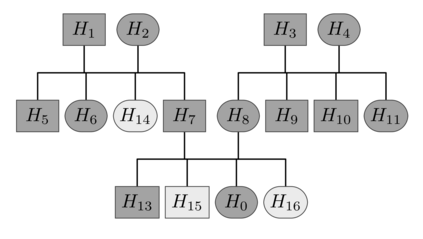
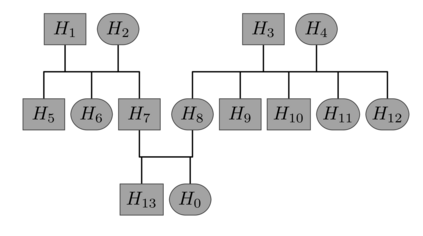
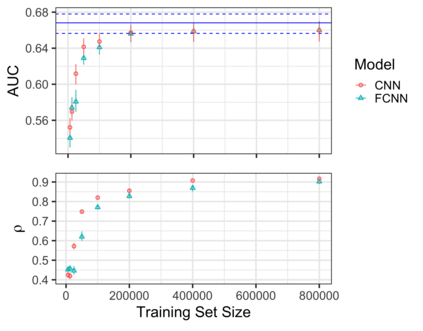
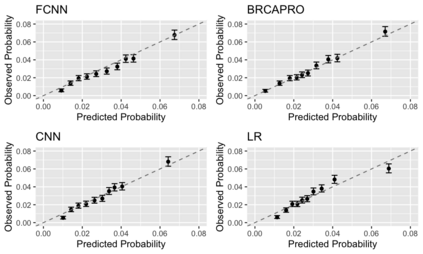
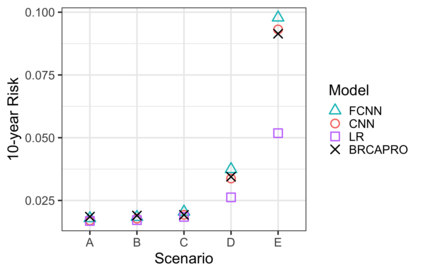
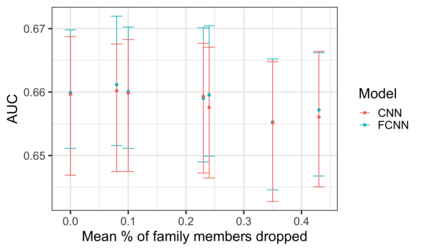
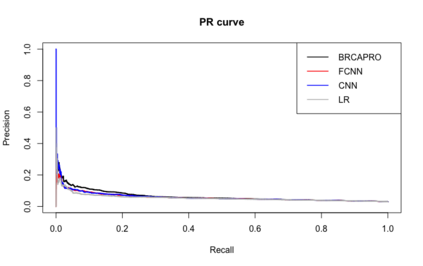
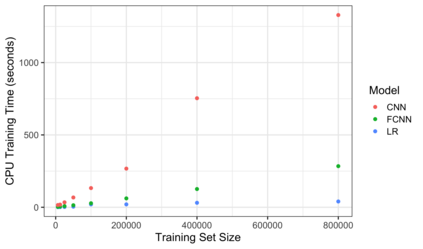
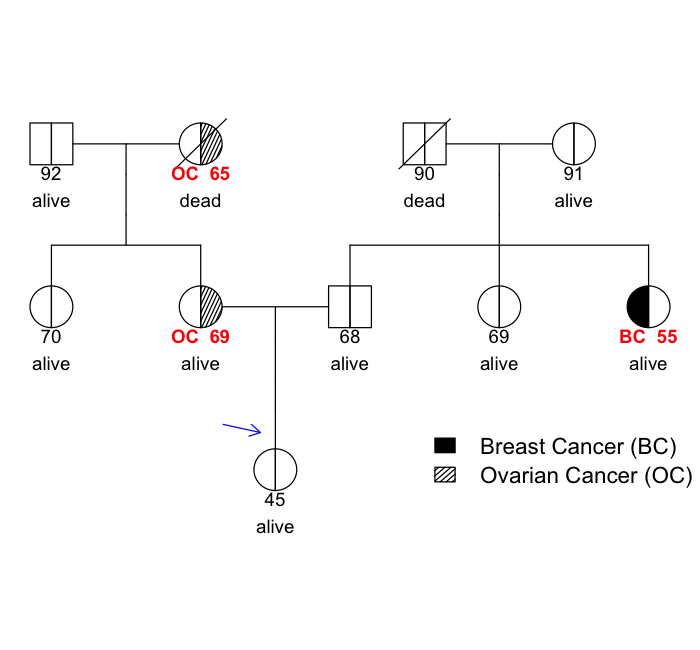
Family history is a major risk factor for many types of cancer. Mendelian risk prediction models translate family histories into cancer risk predictions based on knowledge of cancer susceptibility genes. These models are widely used in clinical practice to help identify high-risk individuals. Mendelian models leverage the entire family history, but they rely on many assumptions about cancer susceptibility genes that are either unrealistic or challenging to validate due to low mutation prevalence. Training more flexible models, such as neural networks, on large databases of pedigrees can potentially lead to accuracy gains. In this paper, we develop a framework to apply neural networks to family history data and investigate their ability to learn inherited susceptibility to cancer. While there is an extensive literature on neural networks and their state-of-the-art performance in many tasks, there is little work applying them to family history data. We propose adaptations of fully-connected neural networks and convolutional neural networks to pedigrees. In data simulated under Mendelian inheritance, we demonstrate that our proposed neural network models are able to achieve nearly optimal prediction performance. Moreover, when the observed family history includes misreported cancer diagnoses, neural networks are able to outperform the Mendelian BRCAPRO model embedding the correct inheritance laws. Using a large dataset of over 200,000 family histories, the Risk Service cohort, we train prediction models for future risk of breast cancer. We validate the models using data from the Cancer Genetics Network.
翻译:家庭史是许多类型癌症的一个主要风险因素。 门德利安风险预测模型将家庭史转化为基于癌症敏感基因知识的癌症风险预测。 这些模型被广泛用于临床实践,以帮助识别高风险个人。 门德利安模型利用了整个家庭历史, 但是他们依赖许多关于癌症敏感基因的假设, 而这些假设由于突变流行率低而既不现实, 或难以验证。 培训更灵活的模型, 如神经网络, 大型血清数据库中的神经网络, 可能导致准确性增益。 在本文中, 我们开发了一个框架, 将神经网络应用于家庭历史数据数据, 并调查其学习癌症遗传性的能力。 虽然关于神经网络的广泛文献及其在许多任务中的最新表现, 但很少将其应用于家庭历史数据数据。 我们建议对完全相连的神经网络和革命神经网络进行改造, 在Mendelian继承中模拟的数据中, 我们提出的神经网络模型能够实现近乎最佳的预测性绩效。 此外, 当所观测到的家庭历史中包含错误的癌症遗传学模型时, 使用巨型癌症风险数据库 。