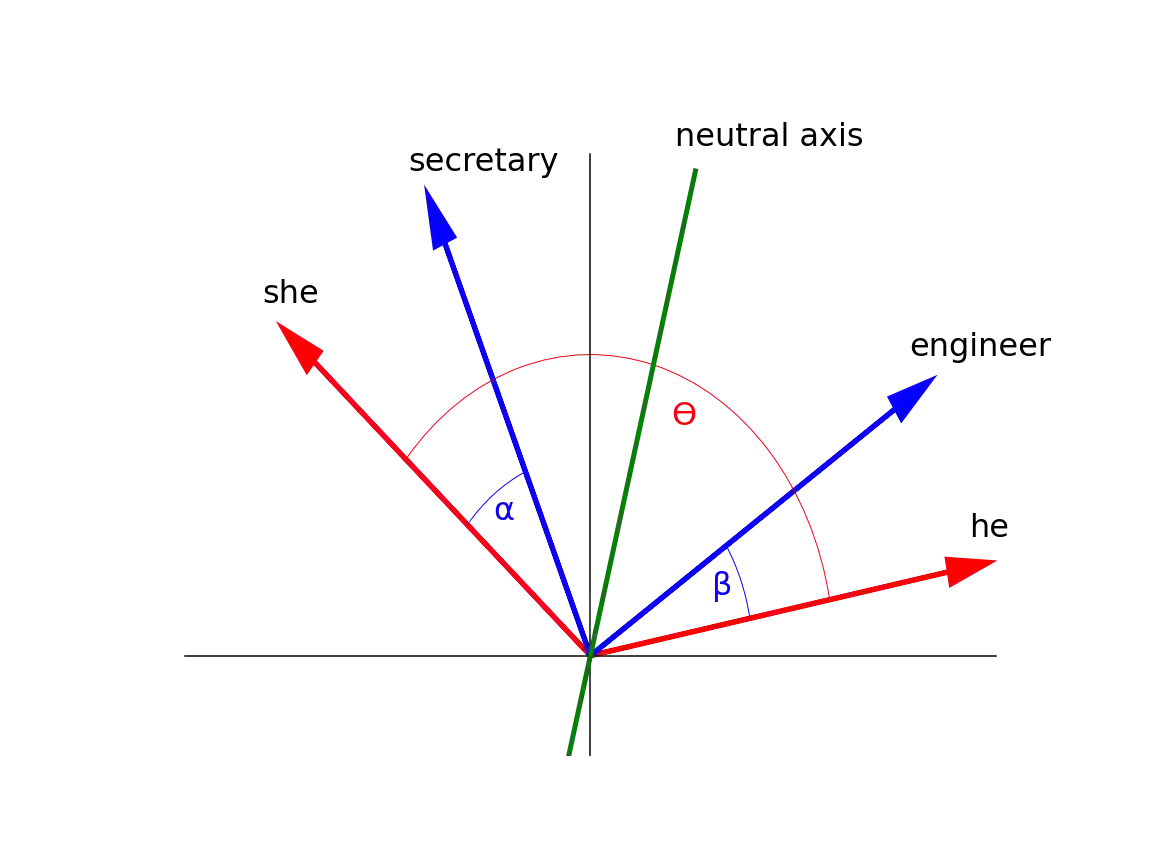
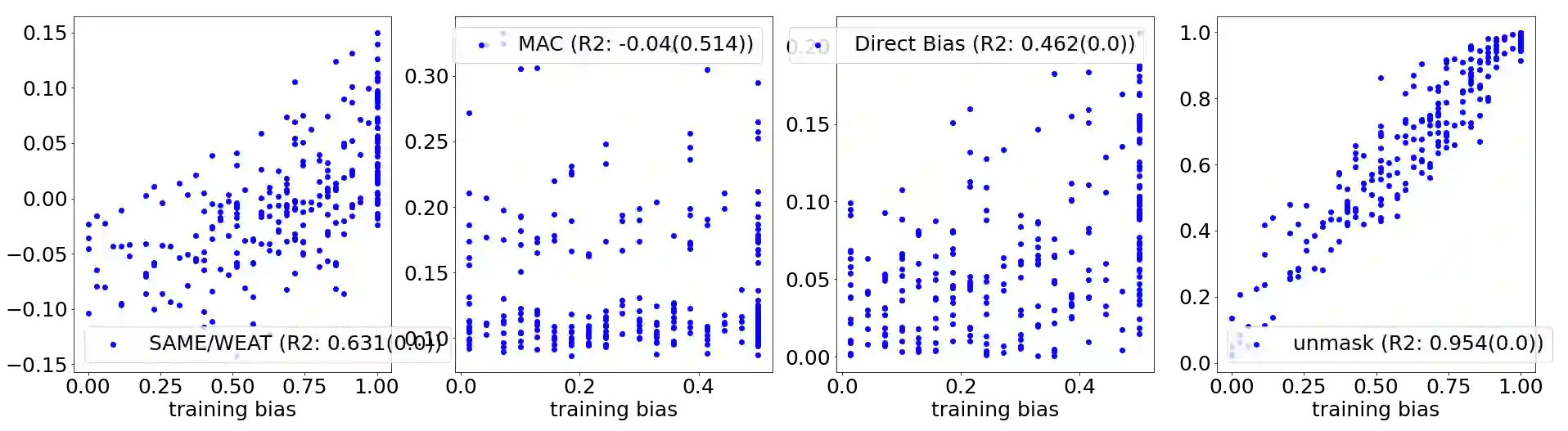
Over the last years, word and sentence embeddings have established as text preprocessing for all kinds of NLP tasks and improved the performances significantly. Unfortunately, it has also been shown that these embeddings inherit various kinds of biases from the training data and thereby pass on biases present in society to NLP solutions. Many papers attempted to quantify bias in word or sentence embeddings to evaluate debiasing methods or compare different embedding models, usually with cosine-based metrics. However, lately some works have raised doubts about these metrics showing that even though such metrics report low biases, other tests still show biases. In fact, there is a great variety of bias metrics or tests proposed in the literature without any consensus on the optimal solutions. Yet we lack works that evaluate bias metrics on a theoretical level or elaborate the advantages and disadvantages of different bias metrics. In this work, we will explore different cosine based bias metrics. We formalize a bias definition based on the ideas from previous works and derive conditions for bias metrics. Furthermore, we thoroughly investigate the existing cosine-based metrics and their limitations to show why these metrics can fail to report biases in some cases. Finally, we propose a new metric, SAME, to address the shortcomings of existing metrics and mathematically prove that SAME behaves appropriately.
翻译:过去几年来,单词和句内嵌嵌式被确定为各种NLP任务的文本预处理,并显著改进了绩效。不幸的是,还显示这些嵌入中继承了培训数据中的各种偏见,从而将社会上存在的偏见传给NLP解决方案。许多文件试图量化文字或句内嵌式中的偏见,以评价贬低性偏向方法,或比较不同的嵌入模式,通常使用基于cosine的衡量标准。然而,最近有些工作使人们对这些衡量标准产生怀疑,显示尽管这类指标报告低偏向,但其他测试仍然显示偏差。事实上,文献中提议的偏见衡量标准或测试有很多种,没有就最佳解决方案达成共识。然而,我们缺乏从理论上评价偏差衡量标准或阐述不同偏差衡量标准的利弊的工作。在这项工作中,我们将探讨基于偏差衡量标准的不同参数。我们根据以往工作的想法正式确定了偏差定义,并提出了偏差度衡量标准的条件。此外,我们彻底调查现有的基于正基指标的计量标准以及它们的限制,以表明文献中提出了各种偏差之处,我们最终能够证明这些衡量标准中的偏差。