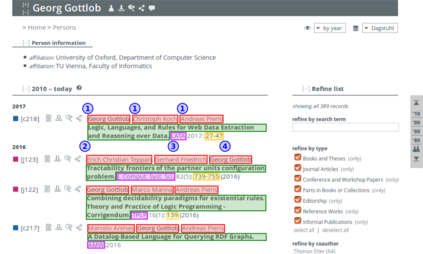
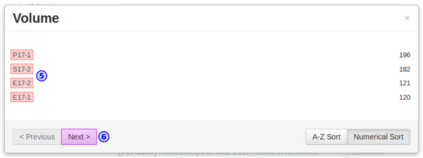
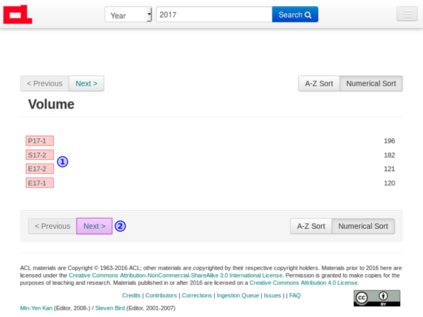
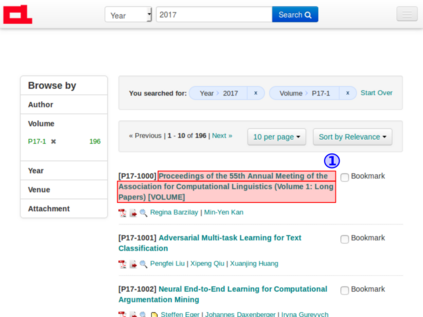
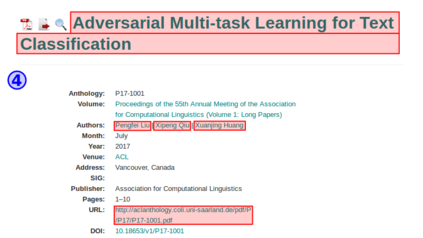
Contemporary web pages with increasingly sophisticated interfaces rival traditional desktop applications for interface complexity and are often called web applications or RIA (Rich Internet Applications). They often require the execution of JavaScript in a web browser and can call AJAX requests to dynamically generate the content, reacting to user interaction. From the automatic data acquisition point of view, thus, it is essential to be able to correctly render web pages and mimic user actions to obtain relevant data from the web page content. Briefly, to obtain data through existing Web interfaces and transform it into structured form, contemporary wrappers should be able to: 1) interact with sophisticated interfaces of web applications; 2) precisely acquire relevant data; 3) scale with the number of crawled web pages or states of web application; 4) have an embeddable programming API for integration with existing web technologies. OXPath is a state-of-the-art technology, which is compliant with these requirements and demonstrated its efficiency in comprehensive experiments. OXPath integrates Firefox for correct rendering of web pages and extends XPath 1.0 for the DOM node selection, interaction, and extraction. It provides means for converting extracted data into different formats, such as XML, JSON, CSV, and saving data into relational databases. This tutorial explains main features of the OXPath language and the setup of a suitable working environment. The guidelines for using OXPath are provided in the form of prototypical examples.
翻译:现代网页,其日益复杂的界面与传统桌面应用程序相对应,其界面复杂,通常被称为网络应用程序或网络应用程序(Rich Internet Application),通常要求在网络浏览器中执行 JavaScript,并可以调用 AJAX 请求,动态生成内容,对用户互动作出反应。因此,从自动获取数据的角度,必须能够正确转换网页和模拟用户行动,以便从网页内容中获取相关数据。简而言之,为了通过现有网络接口获取数据并将其转换成结构化的形式,当代包装商应当能够:(1) 与网络应用程序的复杂接口互动;(2) 准确获取相关数据;(3) 与浏览的网页数量或网络应用程序状态相比,规模;(4) 为与现有网络技术整合而采用嵌入式编程式的API程序;OXPath是一种符合这些要求并在全面试验中展示其效率的状态技术。 OXPath将Fifox纳入网页的正确配置,并将X XPath 1.0 扩展为DOM 节点选择、互动、互动和提取工具;它提供了将数据转换成数据格式的工具,作为CMLS的主要格式的C-PA 格式, 解释了O-PA的C-PA 格式。