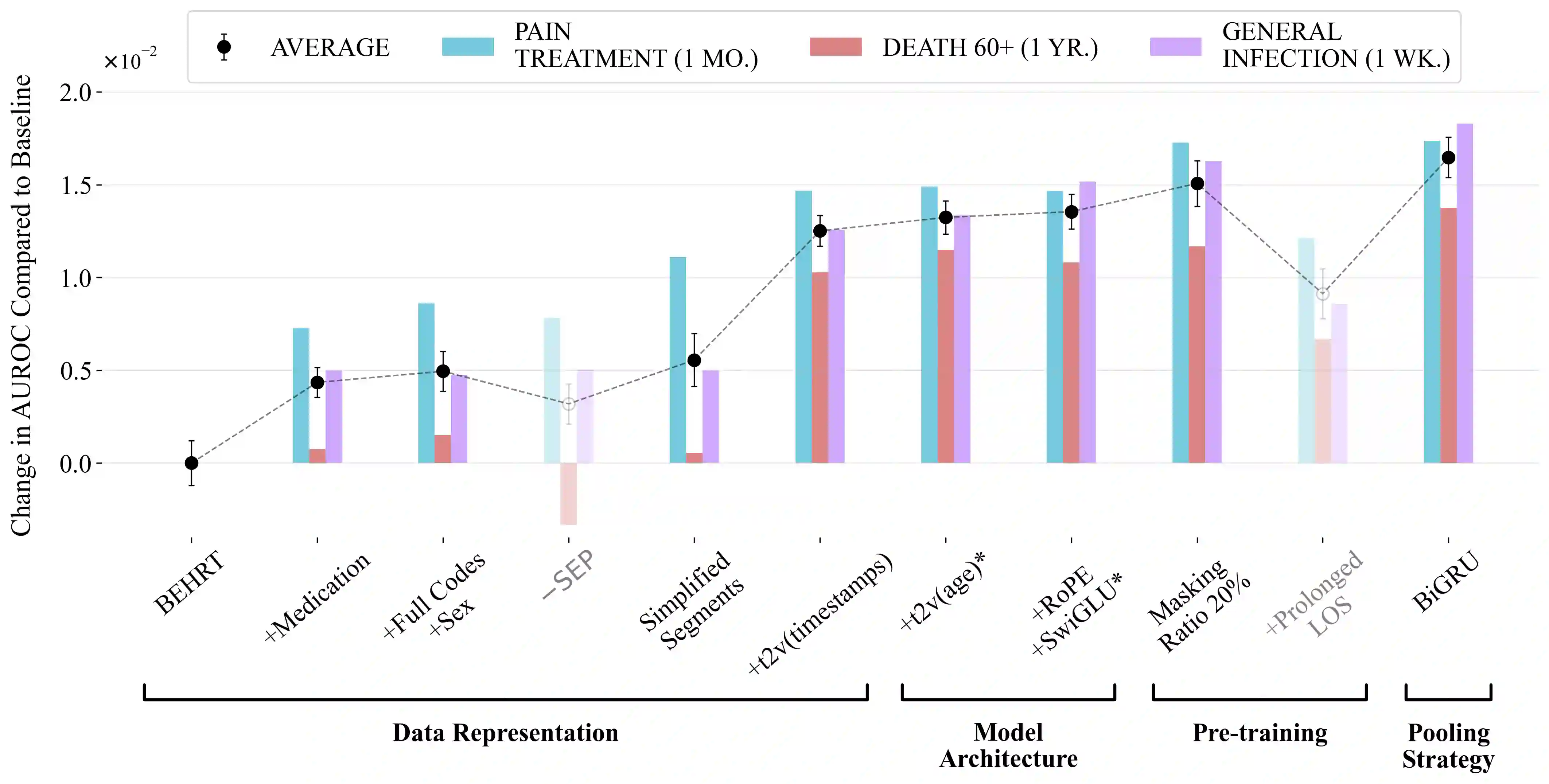
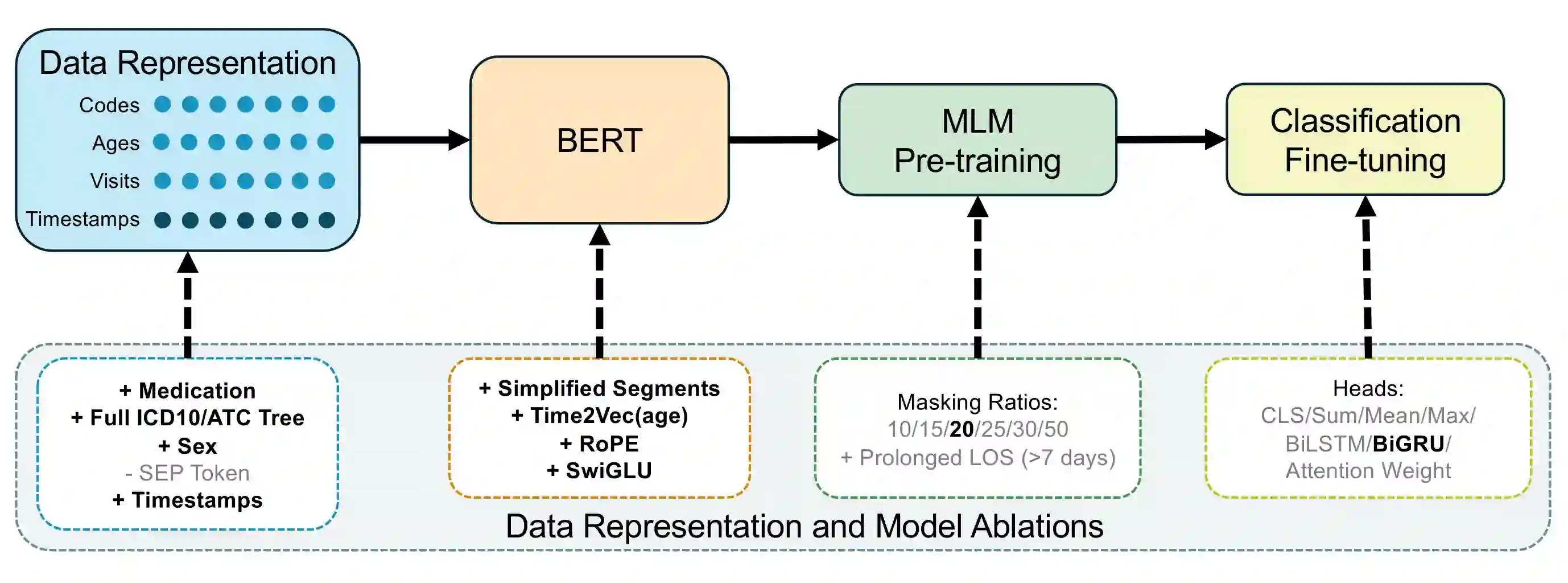
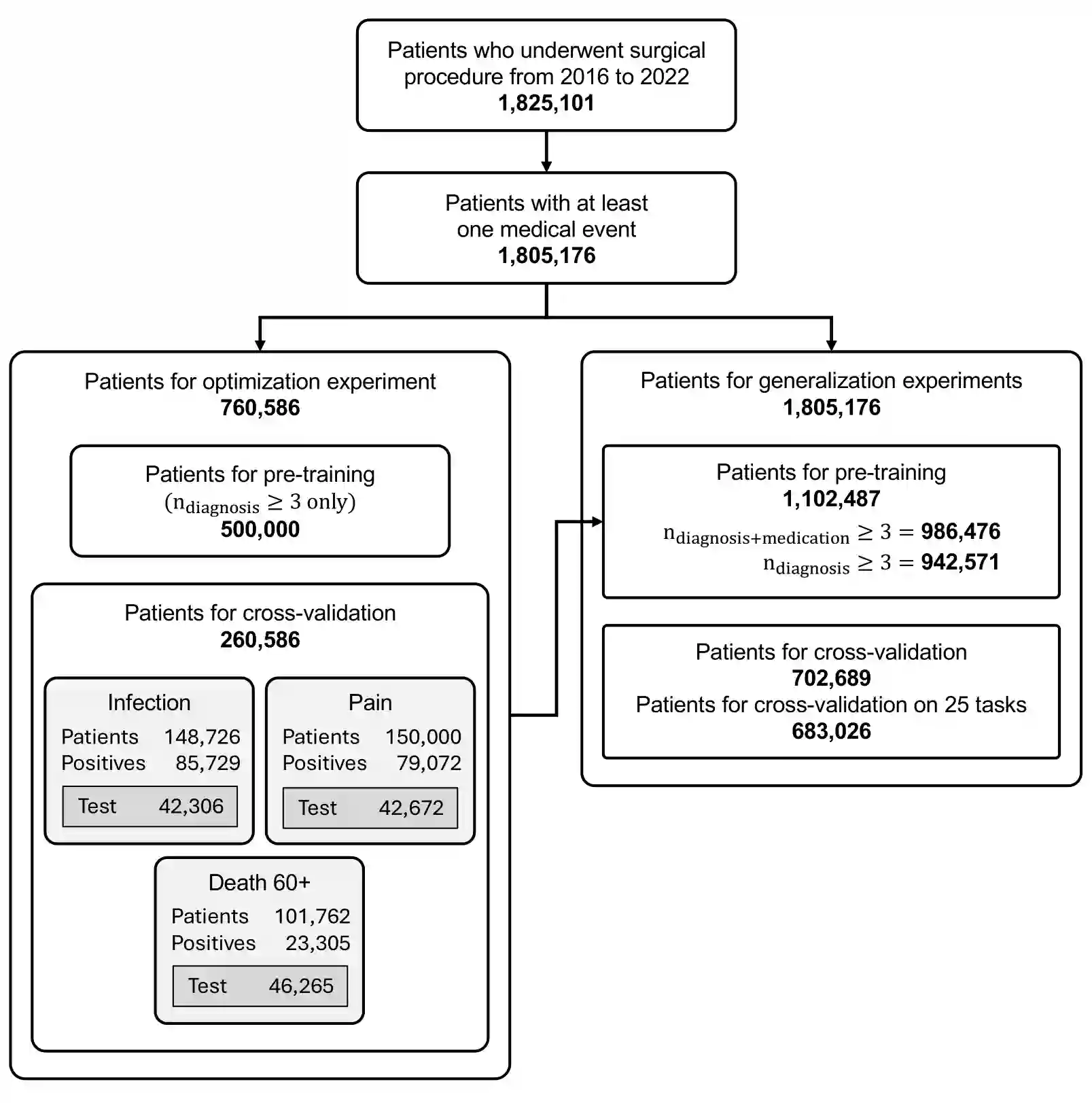
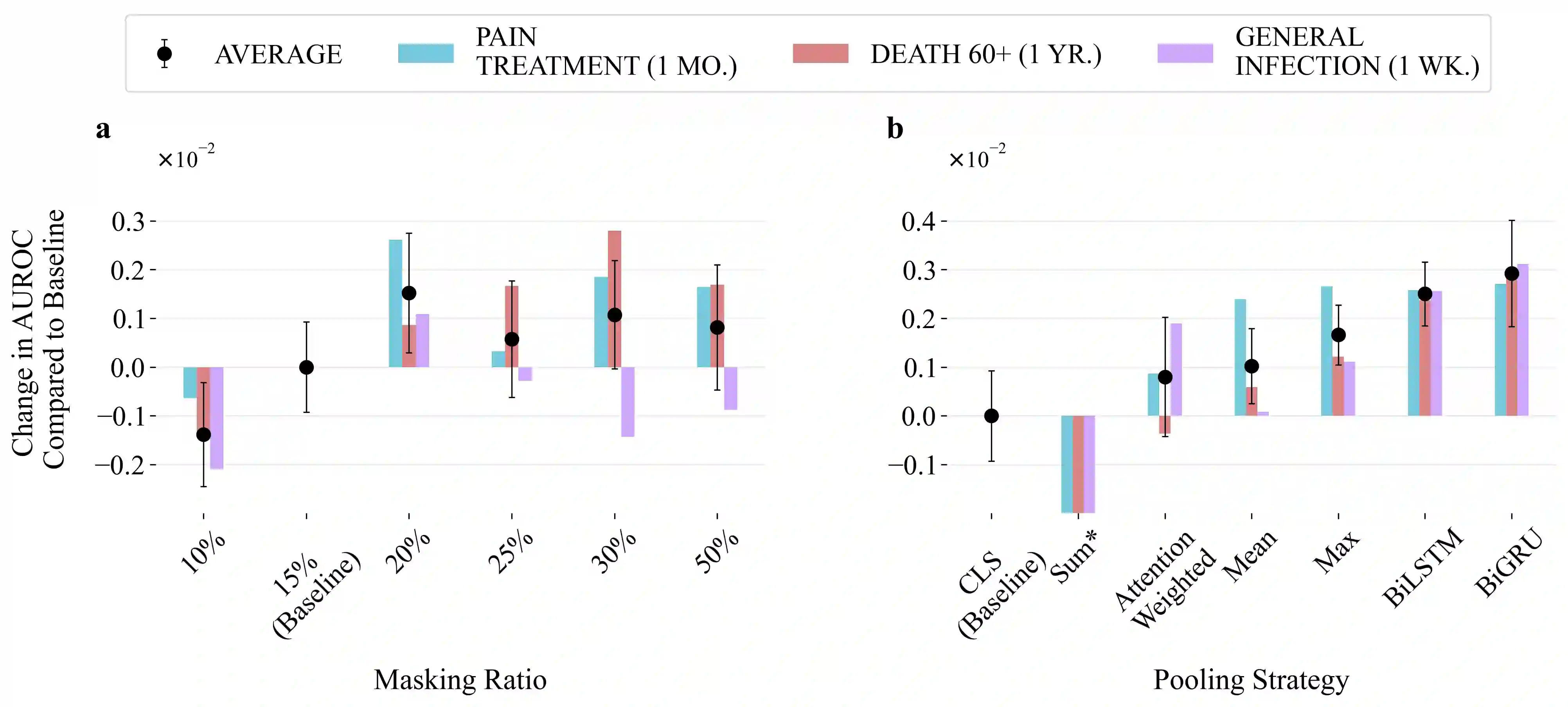
BERT-based models for Electronic Health Records (EHR) have surged in popularity following the release of BEHRT and Med-BERT. Subsequent models have largely built on these foundations despite the fundamental design choices of these pioneering models remaining underexplored. To address this issue, we introduce CORE-BEHRT, a Carefully Optimized and Rigorously Evaluated BEHRT. Through incremental optimization, we isolate the sources of improvement for key design choices, giving us insights into the effect of data representation and individual technical components on performance. Evaluating this across a set of generic tasks (death, pain treatment, and general infection), we showed that improving data representation can increase the average downstream performance from 0.785 to 0.797 AUROC, primarily when including medication and timestamps. Improving the architecture and training protocol on top of this increased average downstream performance to 0.801 AUROC. We then demonstrated the consistency of our optimization through a rigorous evaluation across 25 diverse clinical prediction tasks. We observed significant performance increases in 17 out of 25 tasks and improvements in 24 tasks, highlighting the generalizability of our findings. Our findings provide a strong foundation for future work and aim to increase the trustworthiness of BERT-based EHR models.
翻译:暂无翻译