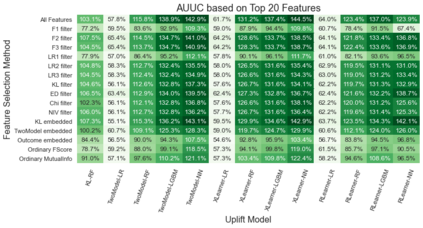
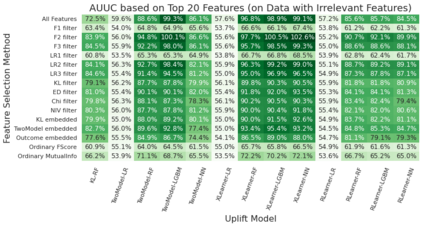
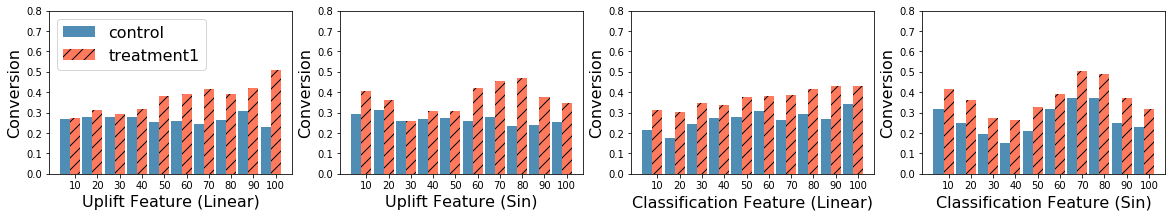Uplift modeling is a causal learning technique that estimates subgroup-level treatment effects. It is commonly used in industry and elsewhere for tasks such as targeting ads. In a typical setting, uplift models can take thousands of features as inputs, which is costly and results in problems such as overfitting and poor model interpretability. Consequently, there is a need to select a subset of the most important features for modeling. However, traditional methods for doing feature selection are not fit for the task because they are designed for standard machine learning models whose target is importantly different from uplift models. To address this, we introduce a set of feature selection methods explicitly designed for uplift modeling, drawing inspiration from statistics and information theory. We conduct empirical evaluations on the proposed methods on publicly available datasets, demonstrating the advantages of the proposed methods compared to traditional feature selection. We make the proposed methods publicly available as a part of the CausalML open-source package.
翻译:升级模型是一种因果学习技术,它估计分层处理效果。它通常用于行业和其他地方,用于诸如定向广告等任务。在典型的设置中,升级模型可以将数千个特征作为投入,成本高昂,导致模型解释能力差等问题。因此,需要选择一组最重要的特征进行模型设计,但传统的特征选择方法不适合这项任务,因为它们是为标准机器学习模型设计的,其目标与升级模型大不相同。为此,我们引入一套特征选择方法,明确设计用于提升模型,从统计和信息理论中提取灵感。我们对公开提供的数据集的拟议方法进行实证评估,展示拟议方法与传统特征选择相比的优势。我们公开提供拟议方法,作为CausalML开放源软件包的一部分。