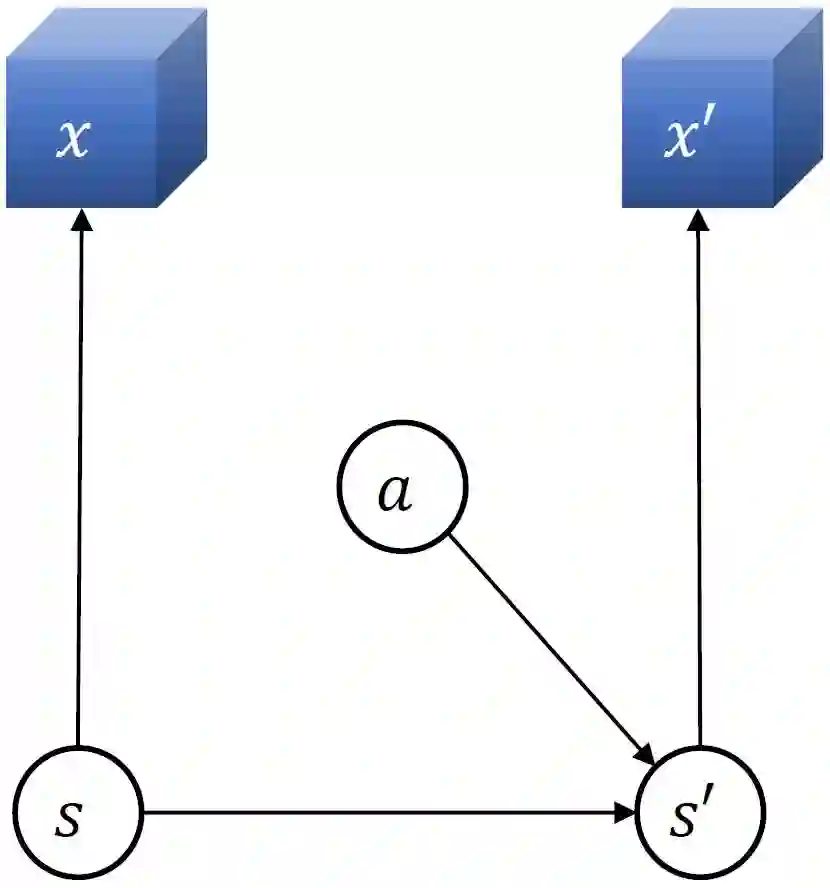
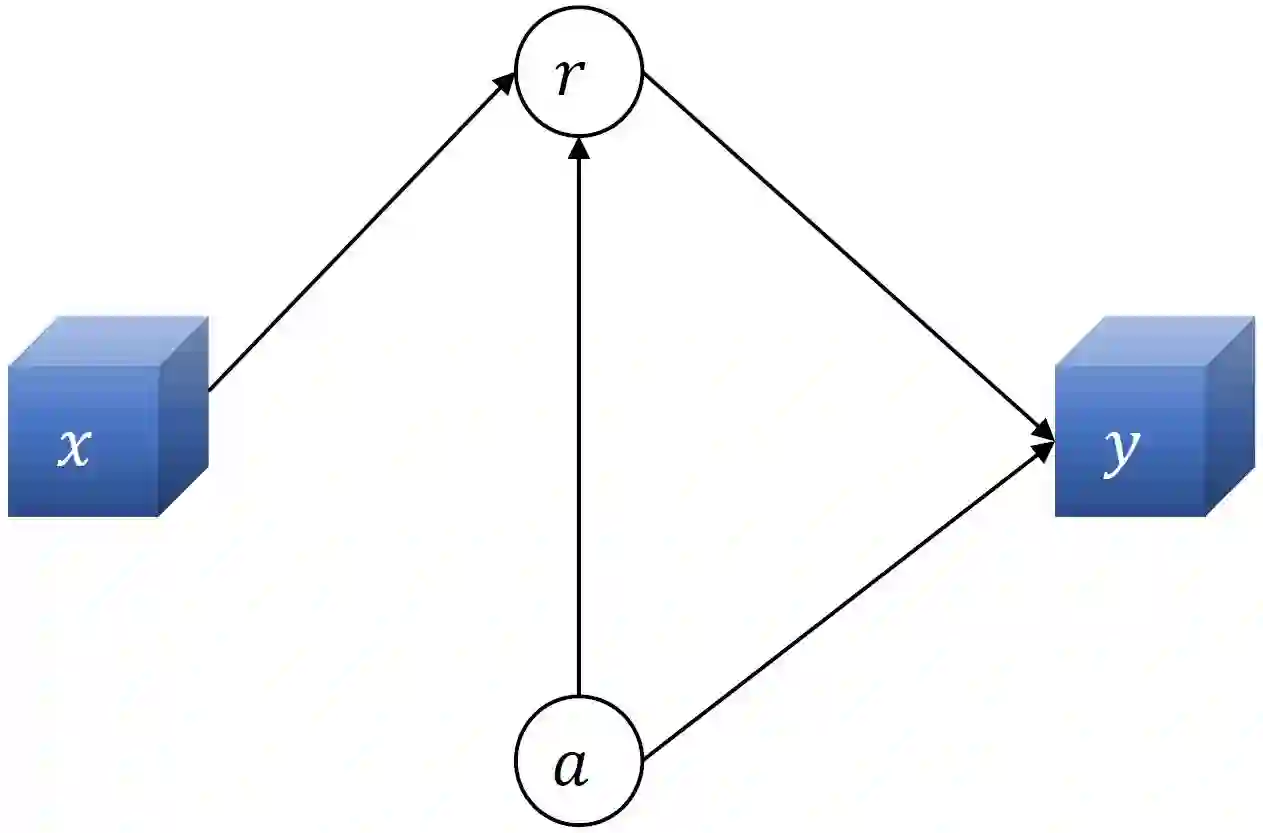
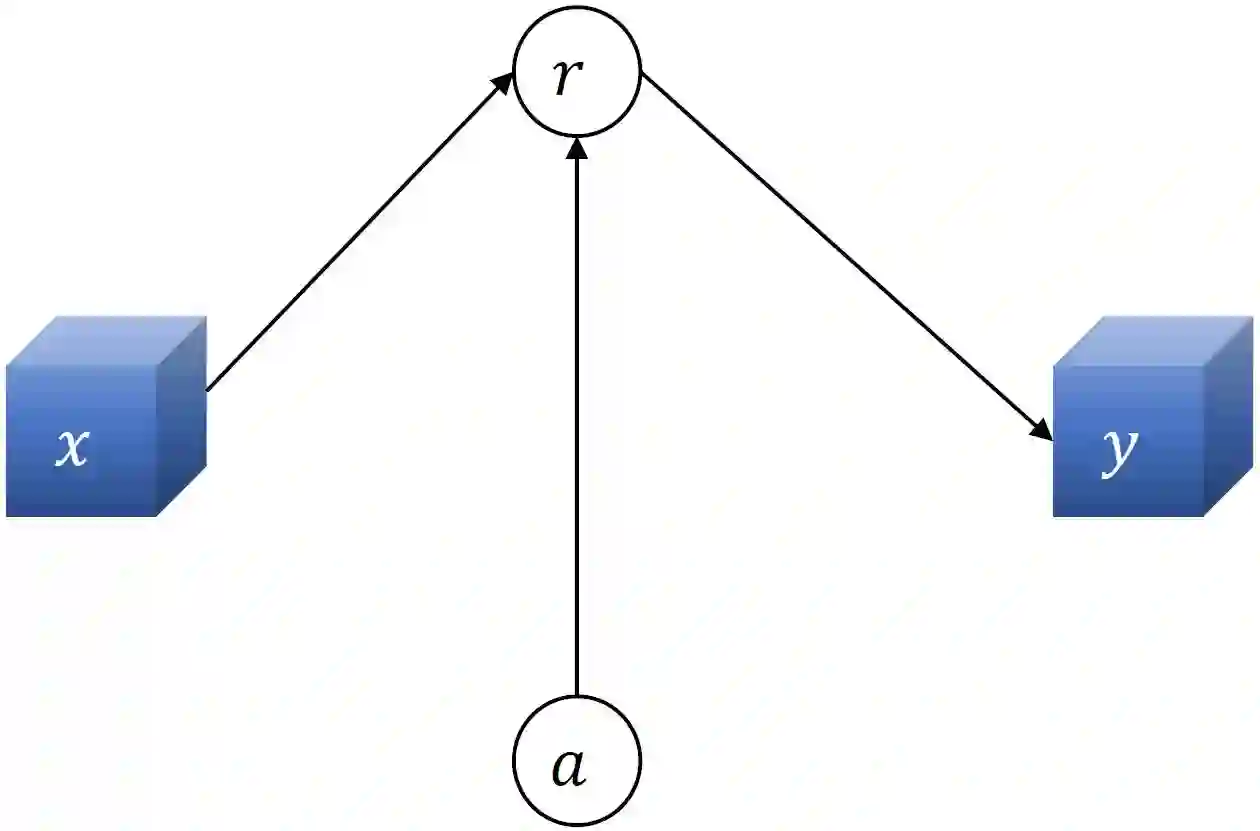
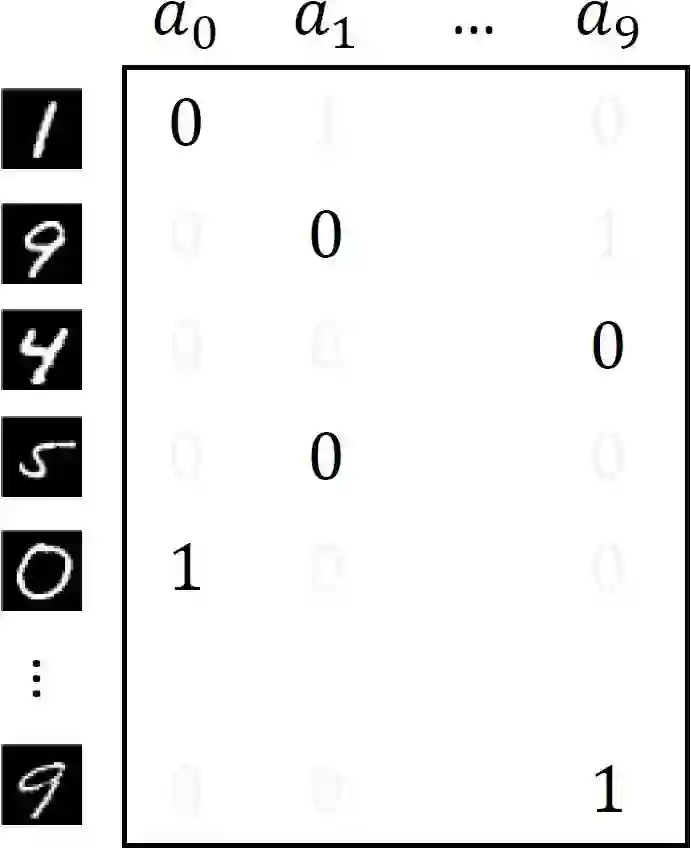
Consider the problem setting of Interaction-Grounded Learning (IGL), in which a learner's goal is to optimally interact with the environment with no explicit reward to ground its policies. The agent observes a context vector, takes an action, and receives a feedback vector, using this information to effectively optimize a policy with respect to a latent reward function. Prior analyzed approaches fail when the feedback vector contains the action, which significantly limits IGL's success in many potential scenarios such as Brain-computer interface (BCI) or Human-computer interface (HCI) applications. We address this by creating an algorithm and analysis which allows IGL to work even when the feedback vector contains the action, encoded in any fashion. We provide theoretical guarantees and large-scale experiments based on supervised datasets to demonstrate the effectiveness of the new approach.
翻译:考虑交互式环球学习(IGL)的问题设置, 学习者的目标是在没有明确奖赏的情况下与环境进行最佳互动, 以确立其政策。 代理人观察上下文矢量, 采取行动, 并接收反馈矢量, 利用这一信息有效优化潜在奖赏功能的政策。 事先分析的方法在反馈矢量包含行动时失败, 这极大地限制了IGL在许多潜在情景中的成功, 如脑计算机接口( BCI) 或 人机接口( HCI) 应用。 我们通过创建算法和分析来解决这个问题, 即使反馈矢量包含行动( 以任何方式编码), 也允许IGL 工作。 我们提供理论保障和大规模实验, 以受监督的数据集为基础, 以证明新方法的有效性 。