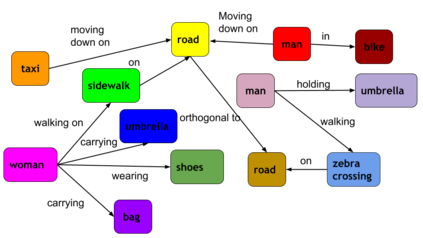
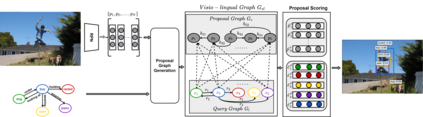
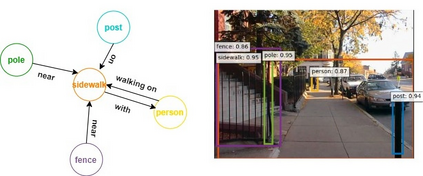
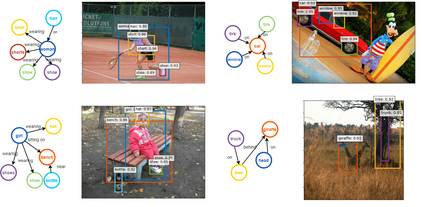
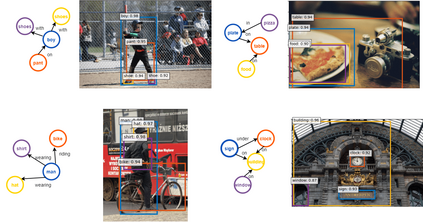
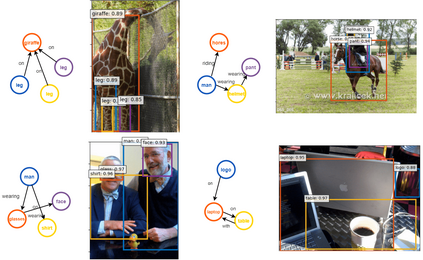
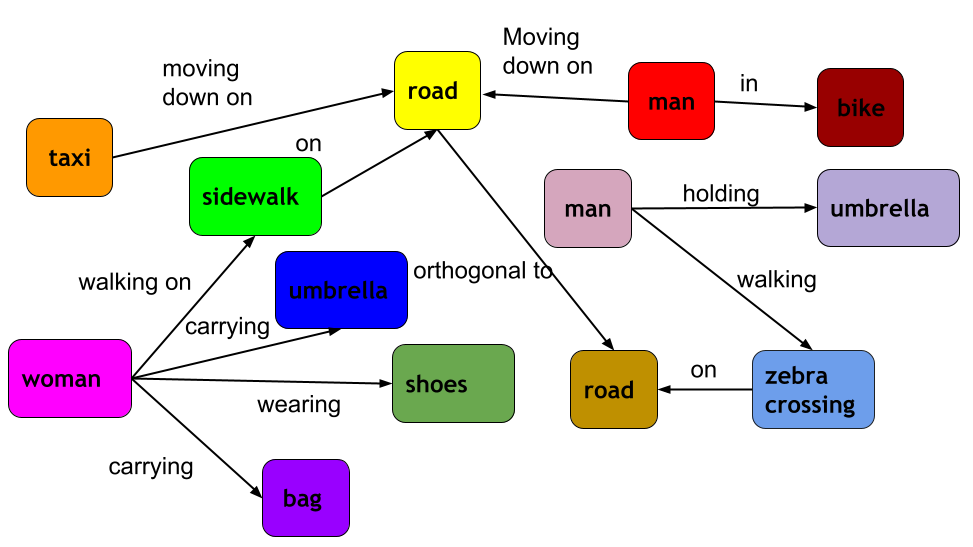
This paper presents a framework for jointly grounding objects that follow certain semantic relationship constraints given in a scene graph. A typical natural scene contains several objects, often exhibiting visual relationships of varied complexities between them. These inter-object relationships provide strong contextual cues toward improving grounding performance compared to a traditional object query-only-based localization task. A scene graph is an efficient and structured way to represent all the objects and their semantic relationships in the image. In an attempt towards bridging these two modalities representing scenes and utilizing contextual information for improving object localization, we rigorously study the problem of grounding scene graphs on natural images. To this end, we propose a novel graph neural network-based approach referred to as Visio-Lingual Message PAssing Graph Neural Network (VL-MPAG Net). In VL-MPAG Net, we first construct a directed graph with object proposals as nodes and an edge between a pair of nodes representing a plausible relation between them. Then a three-step inter-graph and intra-graph message passing is performed to learn the context-dependent representation of the proposals and query objects. These object representations are used to score the proposals to generate object localization. The proposed method significantly outperforms the baselines on four public datasets.
翻译:本文展示了在场景图中遵循某些语义关系限制而联合定位对象的框架。 一个典型的自然场景包含多个对象, 往往展示了它们之间复杂程度不同的视觉关系。 这些对象间关系提供了强大的背景提示, 与传统的对象查询只基于本地化任务相比, 提高了定位性能。 一个场景图是一种高效和结构化的方式, 代表图像中的所有对象及其语义关系。 为了弥合这两种代表场景的模式并利用背景信息来改进天体定位, 我们严格研究自然图像中地貌图的问题。 为此, 我们提出了一个新的图形神经网络基方法, 称为 Visio- Lingal Messingal 图像神经网络( VL-MPAG Net) 。 在 VL- MPAG Net 中, 我们首先用对象建议作为节点, 以及代表对象之间合理关系的一对结点之间的边缘来构建一个定向图形。 然后, 我们进行三步跨线和内线信息传递, 以学习以环境为依托的图像和查询对象的表达方式。 这些天体图表用于显著的排序方法。 这些天体为基准。 这些天体。 这些天体图用于生成的模型。