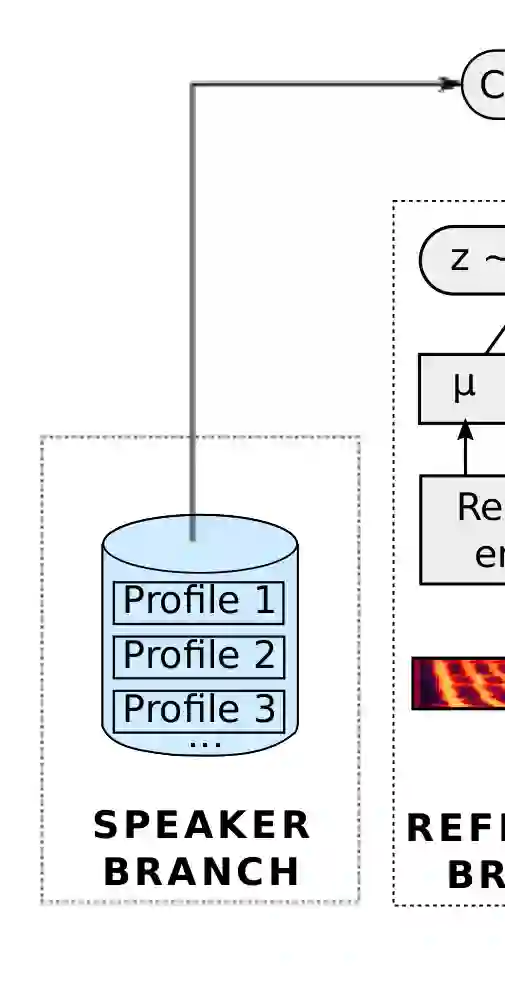
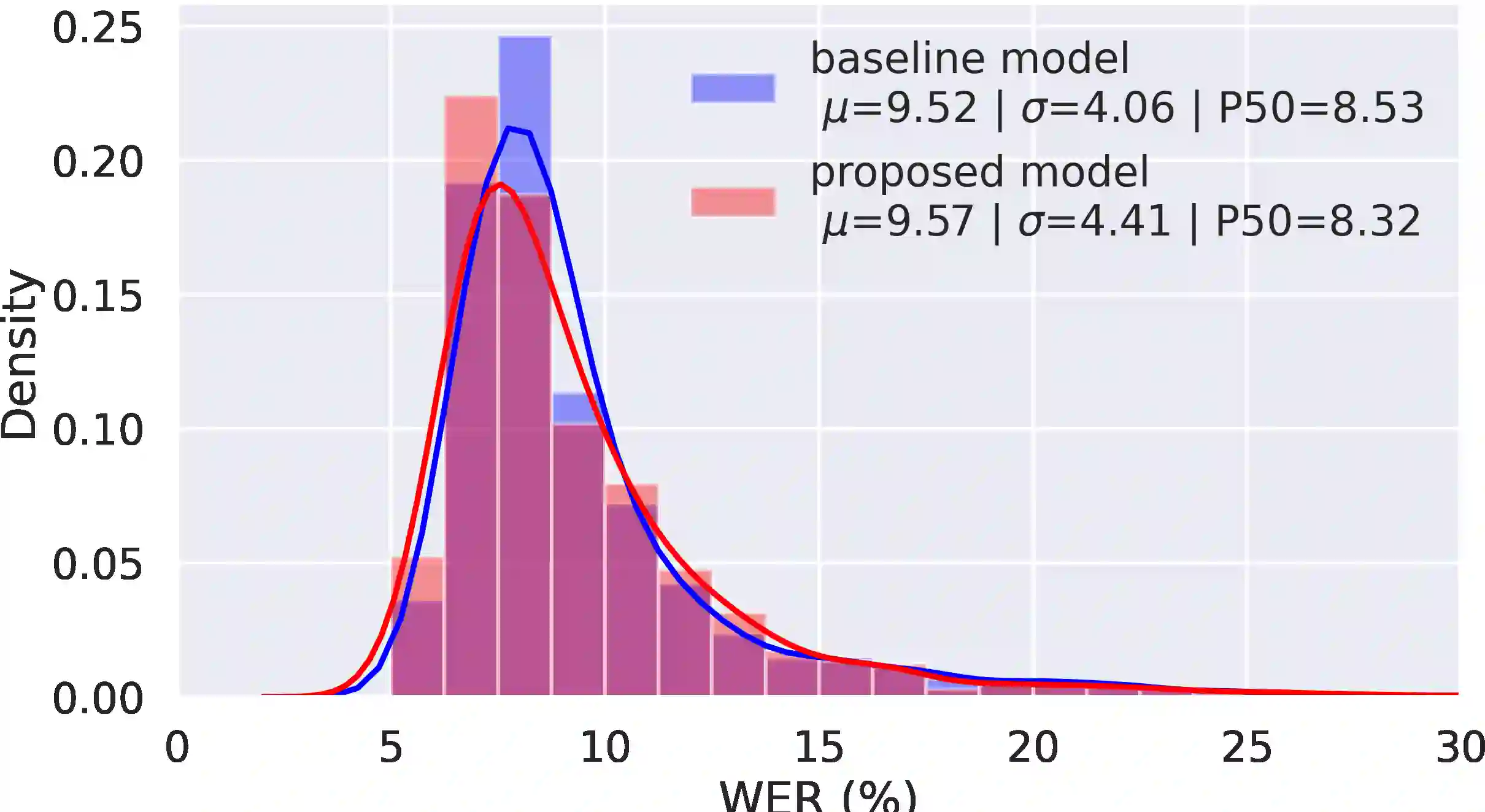
Text-to-speech systems recently achieved almost indistinguishable quality from human speech. However, the prosody of those systems is generally flatter than natural speech, producing samples with low expressiveness. Disentanglement of speaker id and prosody is crucial in text-to-speech systems to improve on naturalness and produce more variable syntheses. This paper proposes a new neural text-to-speech model that approaches the disentanglement problem by conditioning a Tacotron2-like architecture on flow-normalized speaker embeddings, and by substituting the reference encoder with a new learned latent distribution responsible for modeling the intra-sentence variability due to the prosody. By removing the reference encoder dependency, the speaker-leakage problem typically happening in this kind of systems disappears, producing more distinctive syntheses at inference time. The new model achieves significantly higher prosody variance than the baseline in a set of quantitative prosody features, as well as higher speaker distinctiveness, without decreasing the speaker intelligibility. Finally, we observe that the normalized speaker embeddings enable much richer speaker interpolations, substantially improving the distinctiveness of the new interpolated speakers.
翻译:文本到语音系统最近几乎几乎取得了与人说话几乎无法区分的质量。然而,这些系统的摆动一般比自然言语更受宠爱,产生表达力低的样本。在文本到语音系统中,隔开语器id和流体互换对于改进自然特性和产生更多变异的合成物至关重要。本文件提议一种新的神经文本到声音模型,通过在流态发言者嵌入上设置一个像塔可调调调的建筑来应对分解问题,以及用一种新的知识化的潜在分布取代参考编码,以模拟因流态而导致的内感变异。最后,通过取消参考编码依赖性,典型的语器识别和流体互换问题在这类系统中消失,产生更独特的合成物。新模型在数量化变异性特征的基线上,以及更高的发言者的辨别性,同时不降低发言者的可感知性。最后,我们观察到,通过取消参考编码的编码编码,典型的演讲者之间的解析问题通常会消失,产生更鲜明的合成物。