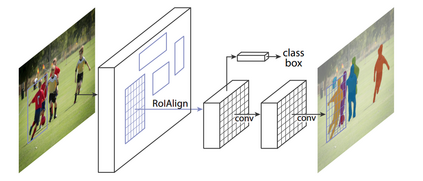
Affordances are the possibilities of actions the environment offers to the individual. Ordinary objects (hammer, knife) usually have many affordances (grasping, pounding, cutting), and detecting these allow artificial agents to understand what are their possibilities in the environment, with obvious application in Robotics. Proposed benchmarks and state-of-the-art prediction models for supervised affordance segmentation are usually modifications of popular object segmentation models such as Mask R-CNN. We observe that theoretically, these popular object segmentation methods should be sufficient for detecting affordances masks. So we ask the question: is it necessary to tailor new architectures to the problem of learning affordances? We show that applying the out-of-the-box Mask R-CNN to the problem of affordances segmentation outperforms the current state-of-the-art. We conclude that the problem of supervised affordance segmentation is included in the problem of object segmentation and argue that better benchmarks for affordance learning should include action capacities.
翻译:负担是环境给个人带来的行动的可能性。 普通物体( 锤子、 刀子) 通常有许多附加物( 剪裁、 剪切), 并检测这些物体使人工代理体能够了解他们在环境中的可能性, 明显地应用在机器人身上。 拟议的基准和最先进的预测模型, 监督配给分割法通常是改变大众物体分割模式, 如Mask R- CNN 。 我们观察到理论上, 这些受欢迎的物体分割法应该足以探测配给物面具。 因此,我们问道: 是否有必要为学习负担能力问题设计新的结构? 我们表明, 将配给制面具 R- CNN 应用在盒子外的配给分解法问题, 超越了目前的状况。 我们得出结论, 受监督的配给分法分割法问题被包括在对象分割法问题中, 并主张更佳的学习基准应该包括行动能力 。