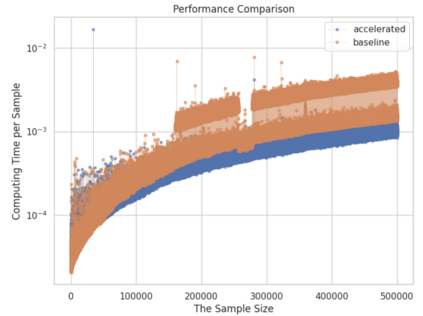
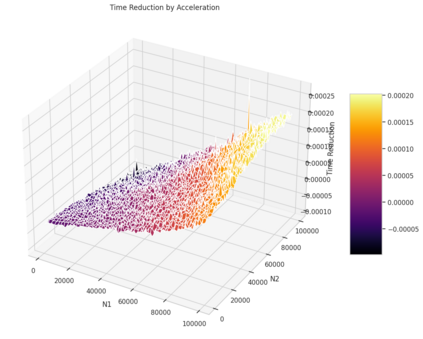
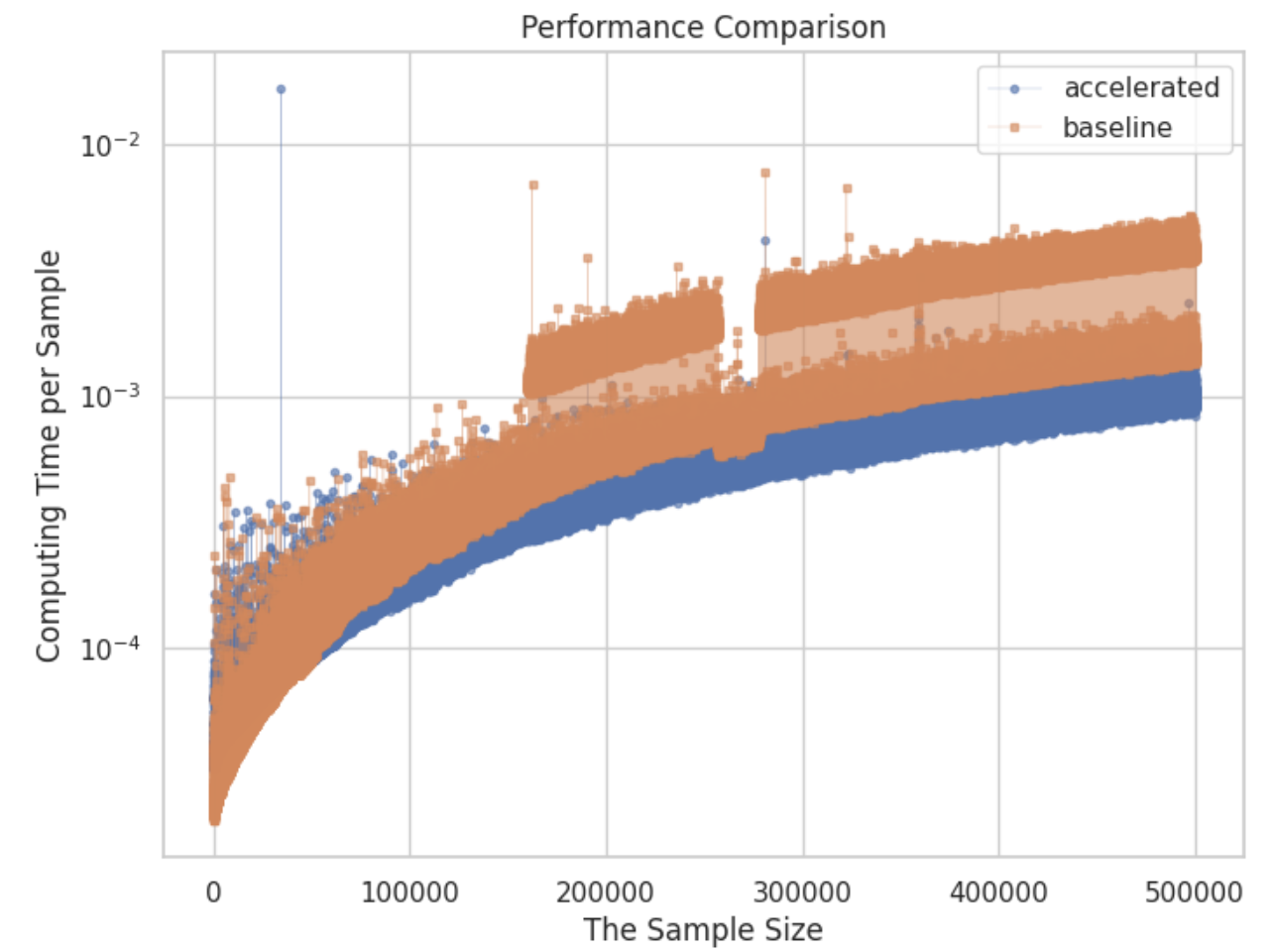
Variance is a basic metric to evaluate the degree of data dispersion, and it is also frequently used in the realm of statistics. However, due to the computing variance and the large dataset being time-consuming, there is an urge to accelerate this computing process. The paper suggests a new method to reduce the time of this computation, it assumes a scenario in which we already know the variance of the original dataset, and the whole variance of this merge dataset could be expressed in the form of addition between the original variance and a remainder term. When we want to calculate the total variance after this adds up, the method only needs to calculate the remainder to get the result instead of recalculating the total variance again, which we named this type of method as PKA(Prior Knowledge Acceleration). The paper mathematically proves the effectiveness of PKA in variance calculation, and the conditions for this method to accelerate properly.
翻译:暂无翻译