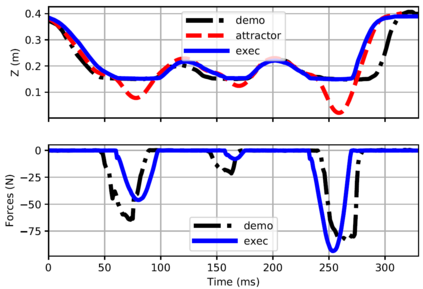
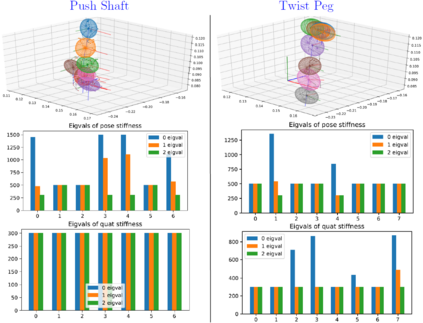
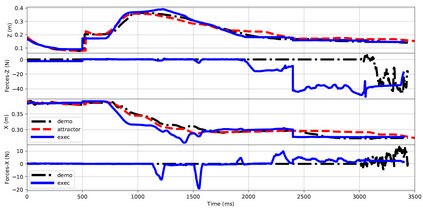
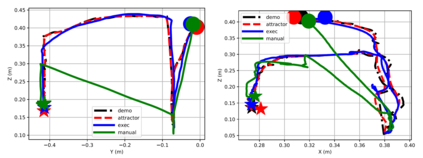
Learning from Demonstration (LfD) provides an intuitive and fast approach to program robotic manipulators. Task parameterized representations allow easy adaptation to new scenes and online observations. However, this approach has been limited to pose-only demonstrations and thus only skills with spatial and temporal features. In this work, we extend the LfD framework to address forceful manipulation skills, which are of great importance for industrial processes such as assembly. For such skills, multi-modal demonstrations including robot end-effector poses, force and torque readings, and operation scene are essential. Our objective is to reproduce such skills reliably according to the demonstrated pose and force profiles within different scenes. The proposed method combines our previous work on task-parameterized optimization and attractor-based impedance control. The learned skill model consists of (i) the attractor model that unifies the pose and force features, and (ii) the stiffness model that optimizes the stiffness for different stages of the skill. Furthermore, an online execution algorithm is proposed to adapt the skill execution to real-time observations of robot poses, measured forces, and changed scenes. We validate this method rigorously on a 7-DoF robot arm over several steps of an E-bike motor assembly process, which require different types of forceful interaction such as insertion, sliding and twisting.
翻译:从演示中学习(LfD) 提供了一种直观和快速的方法来编程机器人操控器。任务参数化的表达方式可以方便地适应新的场景和在线观测。但是,这一方法仅限于只显示演示,因此仅具有空间和时间特点的技能。在这项工作中,我们扩展LfD框架,以解决对组装等工业过程极为重要的强力操纵技能问题。对于这些技能,包括机器人末效力成形、力和透镜在内的多式演示以及操作场景至关重要。我们的目标是根据不同场景中显示的姿势和力形貌,可靠地复制这些技能。拟议的方法将我们以前关于任务分度优化和吸引力制障碍控制的工作结合起来。学习的技能模型包括:(一) 使装容和力特性具有极大重要性的吸引模型,以及(二) 优化不同技能阶段的僵硬性模型。此外,我们提议在线执行算法,使机器人阵容适应对机器人姿势、测量力和变形场景的实时观测。我们在7-DoF型机械机型的滚动过程中严格地验证这一方法。