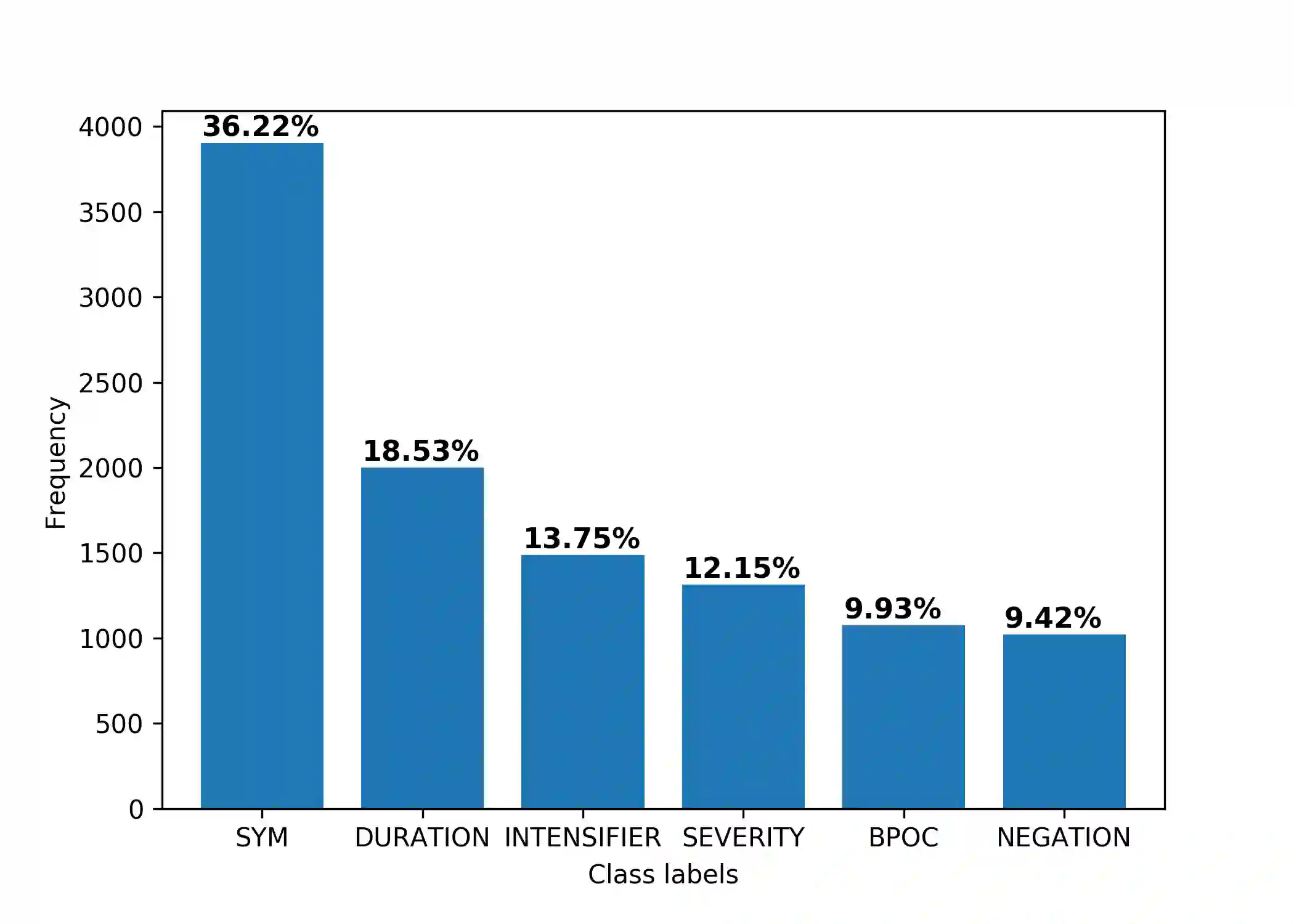
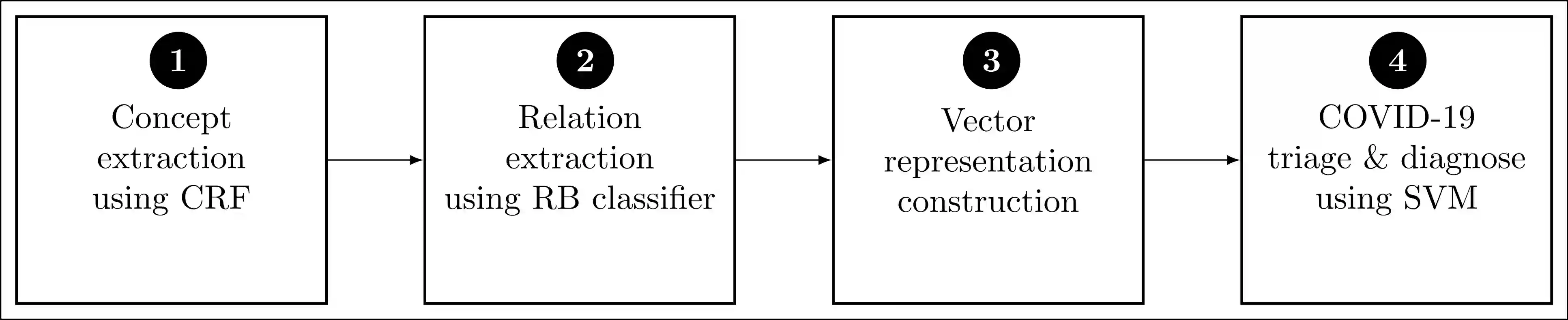
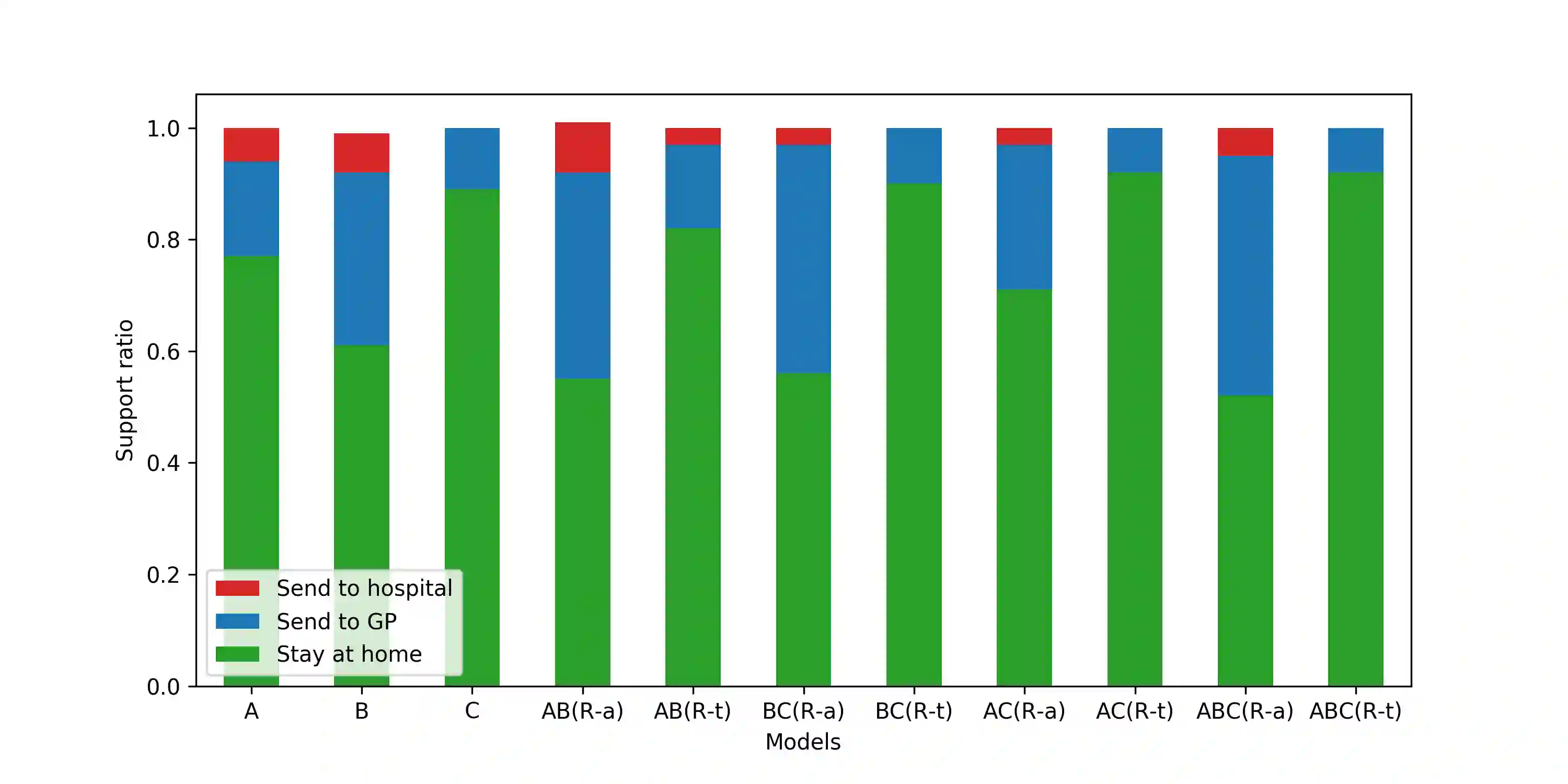
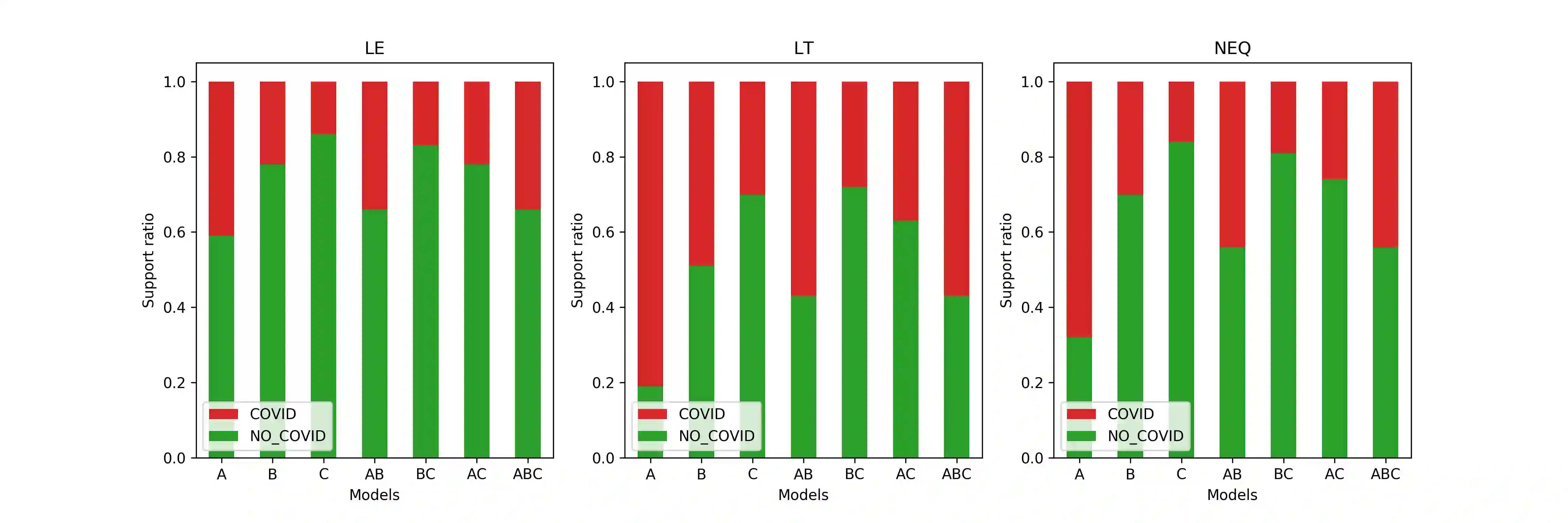
Objective: This study aims to develop an end-to-end natural language processing pipeline for triage and diagnosis of COVID-19 from patient-authored social media posts, in order to provide researchers and public health practitioners with additional information on the symptoms, severity and prevalence of the disease rather than to provide an actionable decision at the individual level. Materials and Methods: The text processing pipeline first extracts COVID-19 symptoms and related concepts such as severity, duration, negations, and body parts from patients' posts using conditional random fields. An unsupervised rule-based algorithm is then applied to establish relations between concepts in the next step of the pipeline. The extracted concepts and relations are subsequently used to construct two different vector representations of each post. These vectors are applied separately to build support vector machine learning models to triage patients into three categories and diagnose them for COVID-19. Results: We report that macro- and micro-averaged F1 scores in the range of 71-96% and 61-87%, respectively, for the triage and diagnosis of COVID-19, when the models are trained on human labelled data. Our experimental results indicate that similar performance can be achieved when the models are trained using predicted labels from concept extraction and rule-based classifiers, thus yielding end-to-end machine learning. Also, we highlight important features uncovered by our diagnostic machine learning models and compare them with the most frequent symptoms revealed in another COVID-19 dataset. In particular, we found that the most important features are not always the most frequent ones.
翻译:目标:本研究旨在开发一种端到端的自然语言处理管道,从病人使用的社交媒体站点对COVID-19进行分级和诊断,以便从病人使用的社交媒体站点对COVID-19进行分级和诊断。 以便向研究人员和公共卫生从业人员提供关于该疾病的症状、严重程度和流行程度的更多信息,而不是提供个人一级可采取行动的决定。 材料和方法:文本处理管道首先提取病人的COVID-19症状和相关概念,如严重程度、持续时间、否定和身体部位,使用有条件随机字段。然后应用一种不受监督的基于规则的算法,在管道的下一步建立概念之间的关系。 提取的概念和经常特征随后被用来建立两个不同的矢量表。 这些矢量被分别用来建立支持矢量机的学习模型,将病人分为三类并诊断COVI-19。 结果:我们报告说,在对COVI-19的分级和体部位分别进行71-96%和61-87%的分级平均F1分级评分数。 当模型在人类标签的下一个重要数据模型上得到训练时,我们最经常的对比结果显示,我们通过在最后的评分级的评分级模型中可以实现。