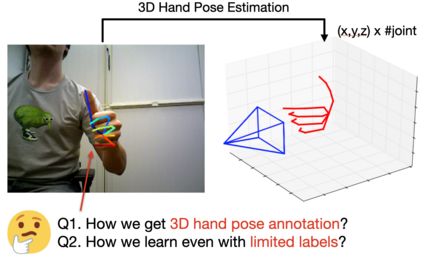
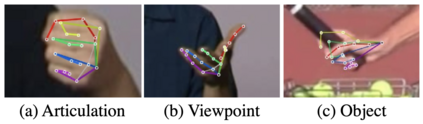
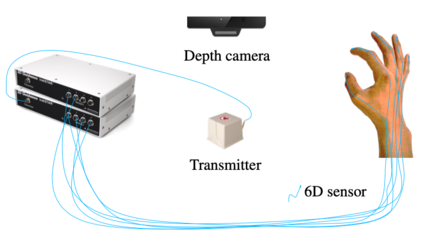
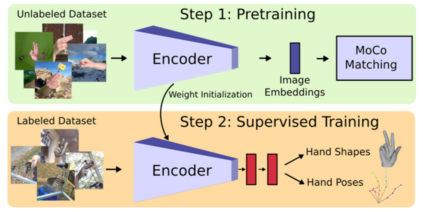
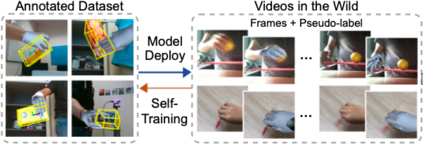
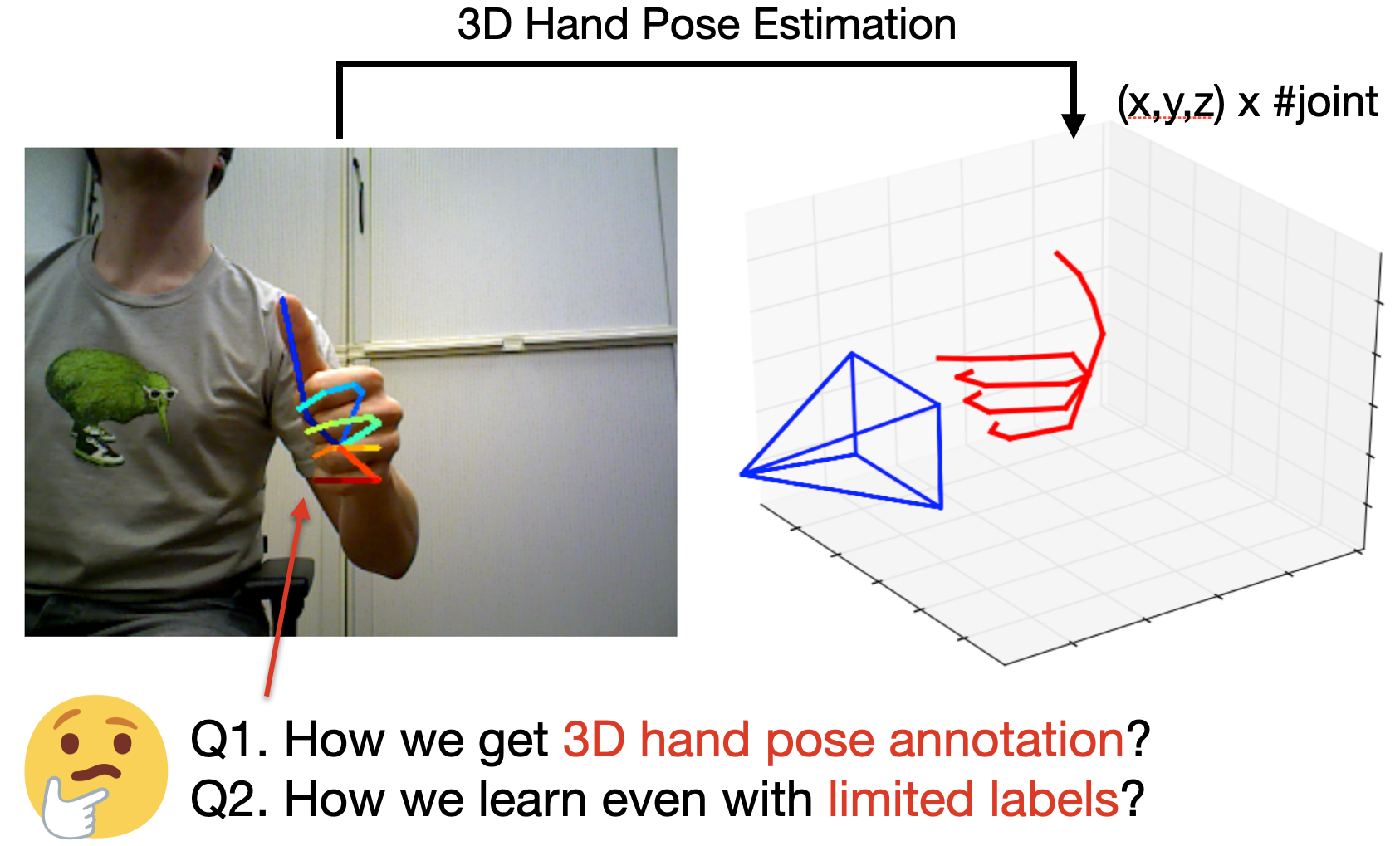
In this survey, we present comprehensive analysis of 3D hand pose estimation from the perspective of efficient annotation and learning. In particular, we study recent approaches for 3D hand pose annotation and learning methods with limited annotated data. In 3D hand pose estimation, collecting 3D hand pose annotation is a key step in developing hand pose estimators and their applications, such as video understanding, AR/VR, and robotics. However, acquiring annotated 3D hand poses is cumbersome, e.g., due to the difficulty of accessing 3D information and occlusion. Motivated by elucidating how recent works address the annotation issue, we investigated annotation methods classified as manual, synthetic-model-based, hand-sensor-based, and computational approaches. Since these annotation methods are not always available on a large scale, we examined methods of learning 3D hand poses when we do not have enough annotated data, namely self-supervised pre-training, semi-supervised learning, and domain adaptation. Based on the analysis of these efficient annotation and learning, we further discuss limitations and possible future directions of this field.
翻译:在本次调查中,我们从高效说明和学习的角度对3D手构成估计进行综合分析,特别是研究最近对3D手采用的方法提出了说明和学习方法,附有有限的附加说明的数据;在3D手进行估计,收集3D手作出说明是开发手表显示估计器及其应用,如视频理解、AR/VR和机器人等的关键一步;然而,由于难以获得3D手作出附加说明,获取3D手作出说明是累赘的,例如,由于难以获得3D信息和隔离。我们研究最近的工作如何解决说明问题,我们调查了说明方法,将其归类为人工、合成模型、人工传感器和计算方法。由于这些说明方法并非总能大规模提供,因此,当我们没有足够的附加说明性数据,即自我控制培训前、半超强学习和领域适应,我们考察了3D手作出说明的方法。我们根据对这些高效率说明和学习的分析,进一步讨论了这一领域的限制和可能的未来方向。