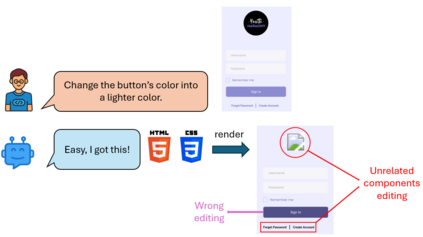
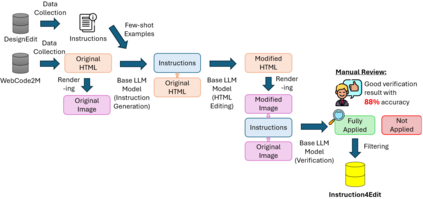
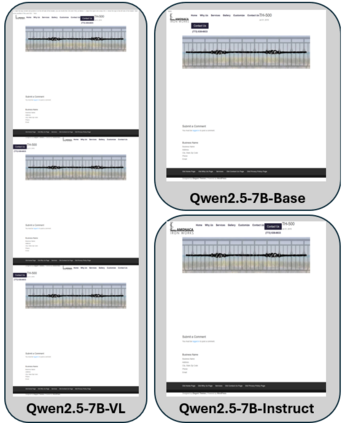
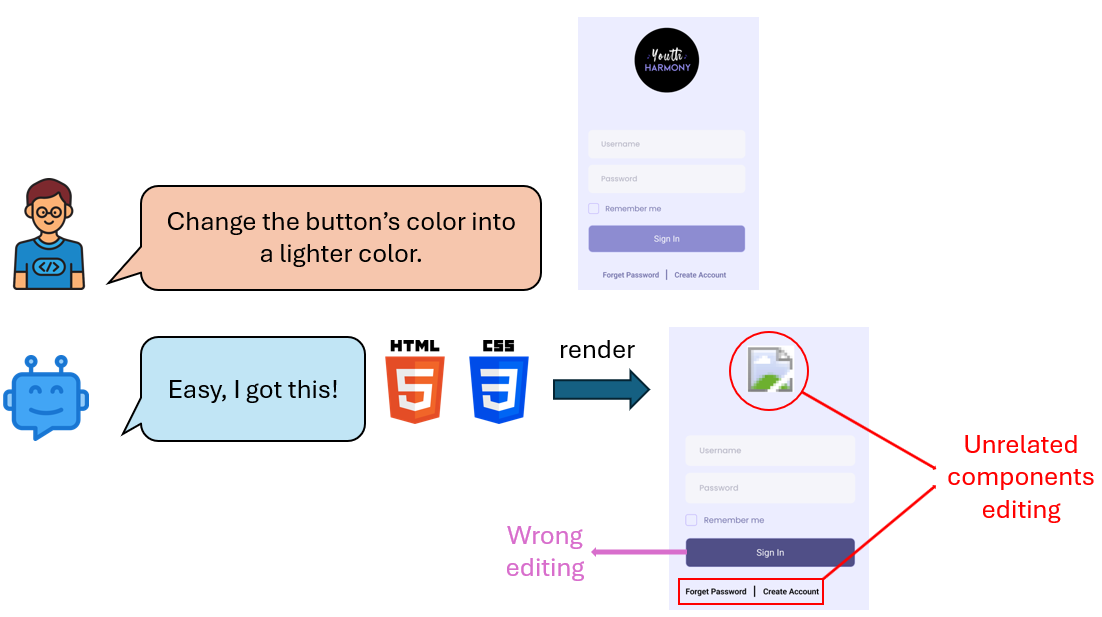
The evolution of web applications relies on iterative code modifications, a process that is traditionally manual and time-consuming. While Large Language Models (LLMs) can generate UI code, their ability to edit existing code from new design requirements (e.g., "center the logo") remains a challenge. This is largely due to the absence of large-scale, high-quality tuning data to align model performance with human expectations. In this paper, we introduce a novel, automated data generation pipeline that uses LLMs to synthesize a high-quality fine-tuning dataset for web editing, named Instruct4Edit. Our approach generates diverse instructions, applies the corresponding code modifications, and performs visual verification to ensure correctness. By fine-tuning models on Instruct4Edit, we demonstrate consistent improvement in translating human intent into precise, structurally coherent, and visually accurate code changes. This work provides a scalable and transparent foundation for natural language based web editing, demonstrating that fine-tuning smaller open-source models can achieve competitive performance with proprietary systems. We release all data, code implementations, and model checkpoints for reproduction.
翻译:暂无翻译