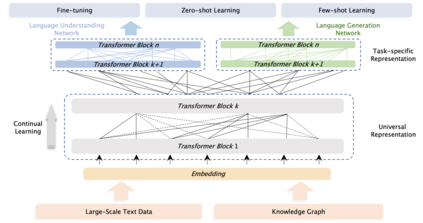
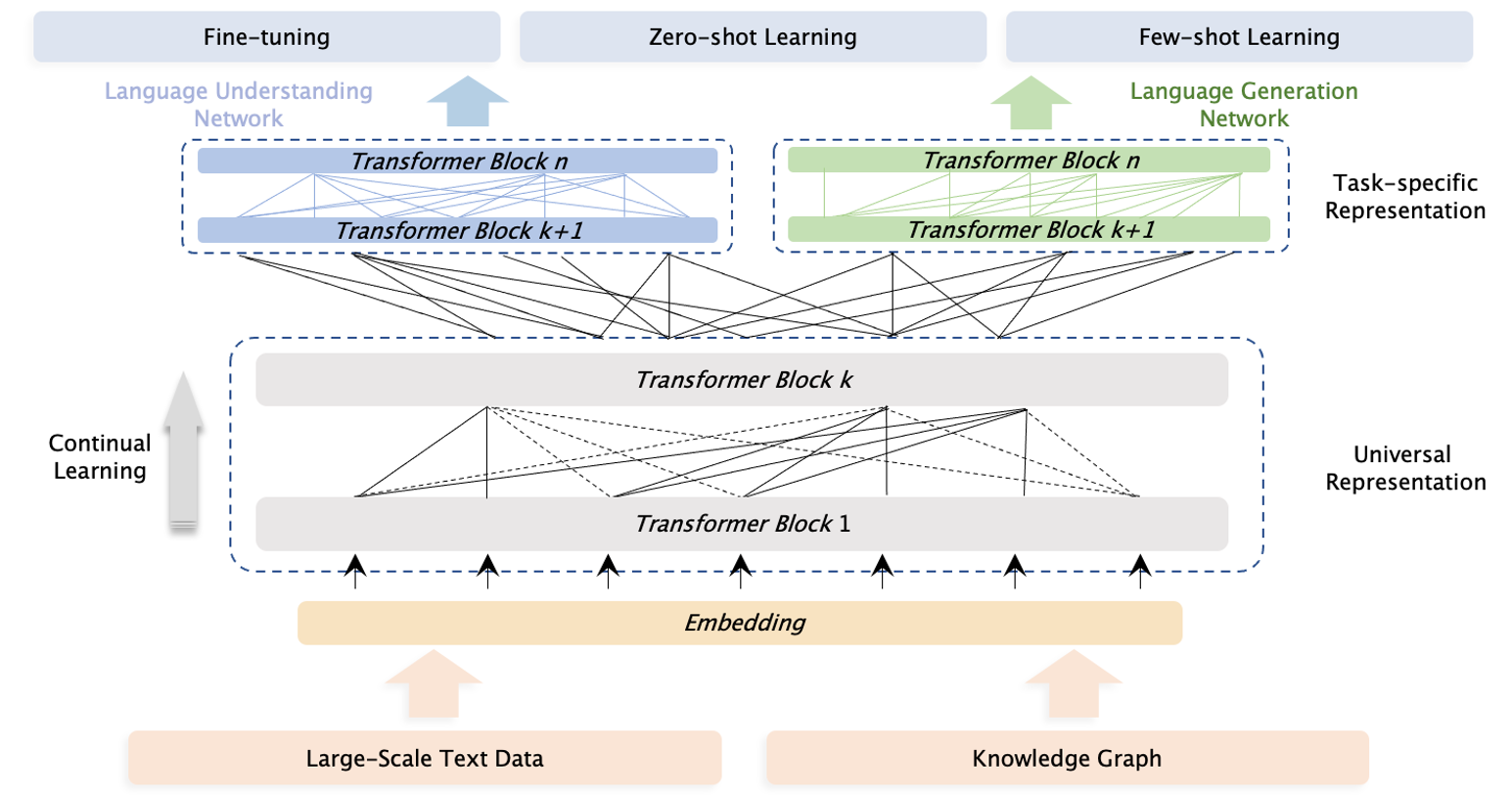
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
翻译:诸如T5和GPT-3等近期工作显示,在解决下游语言理解任务时,这种传统的微调方法显示,在解决下游语言理解任务时,业绩表现相对较低。为了解决上述问题,我们提议了一个名为ERNIE 3.0的统一框架,用于培训大规模知识强化模型。它结合了自动反向网络和自动编码网络,这样,经过培训的模型可以很容易地适应自然语言理解和生成任务,包括零射学习、少量学习或微调。我们用10亿个基准参数来培训由54%的平面文字和大规模知识提升模型组成的4亿PLV8模型。