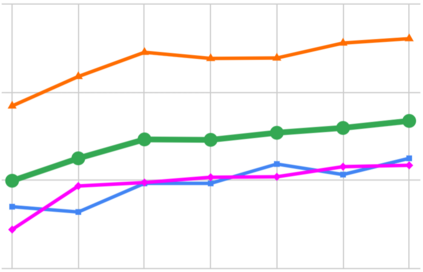
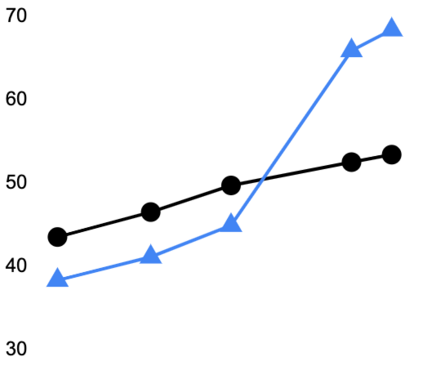
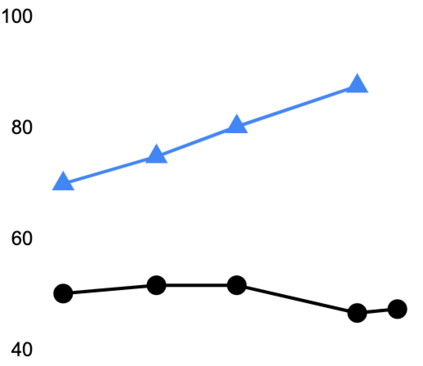
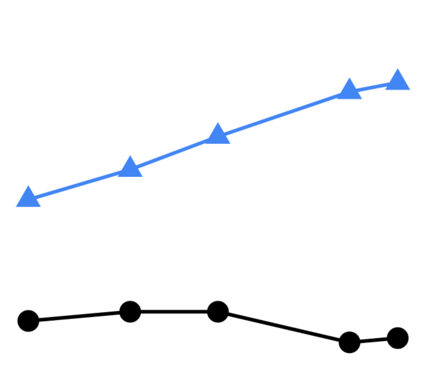
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning -- finetuning language models on a collection of tasks described via instructions -- substantially boosts zero-shot performance on unseen tasks. We take a 137B parameter pretrained language model and instruction-tune it on over 60 NLP tasks verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 19 of 25 tasks that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of tasks and model scale are key components to the success of instruction tuning.
翻译:本文探索了提高语言模式零点学习能力的简单方法。我们展示了教学调整 -- -- 微调通过指令描述的任务集的语言模型 -- -- 极大地提升了无法完成的任务的零点性能。我们采用了137B参数预先培训的语言模型,并用自然语言教学模板对超过60个NLP任务进行了教学。我们用未知任务类型来评价这个我们称之为FLAN的规范调整模式。FLAN大大改进了其未修改对应方的性能,在我们评估的25项任务中的19项任务中超过了175B GPT-3号。FLAN甚至以ANLI、RTE、BolQ、AI2-ARC、OpenbookQA和StoryCloze的很大幅度比微小的GPT-3号高出了几发GPT-3号。Abl研究显示,任务和模型规模的数目是指导调整取得成功的关键组成部分。