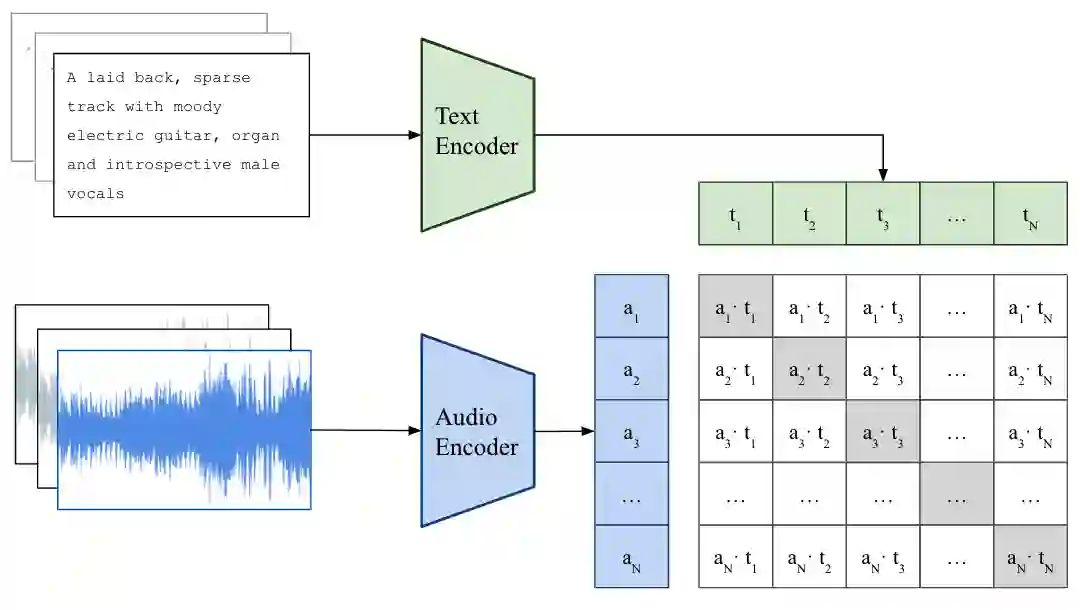
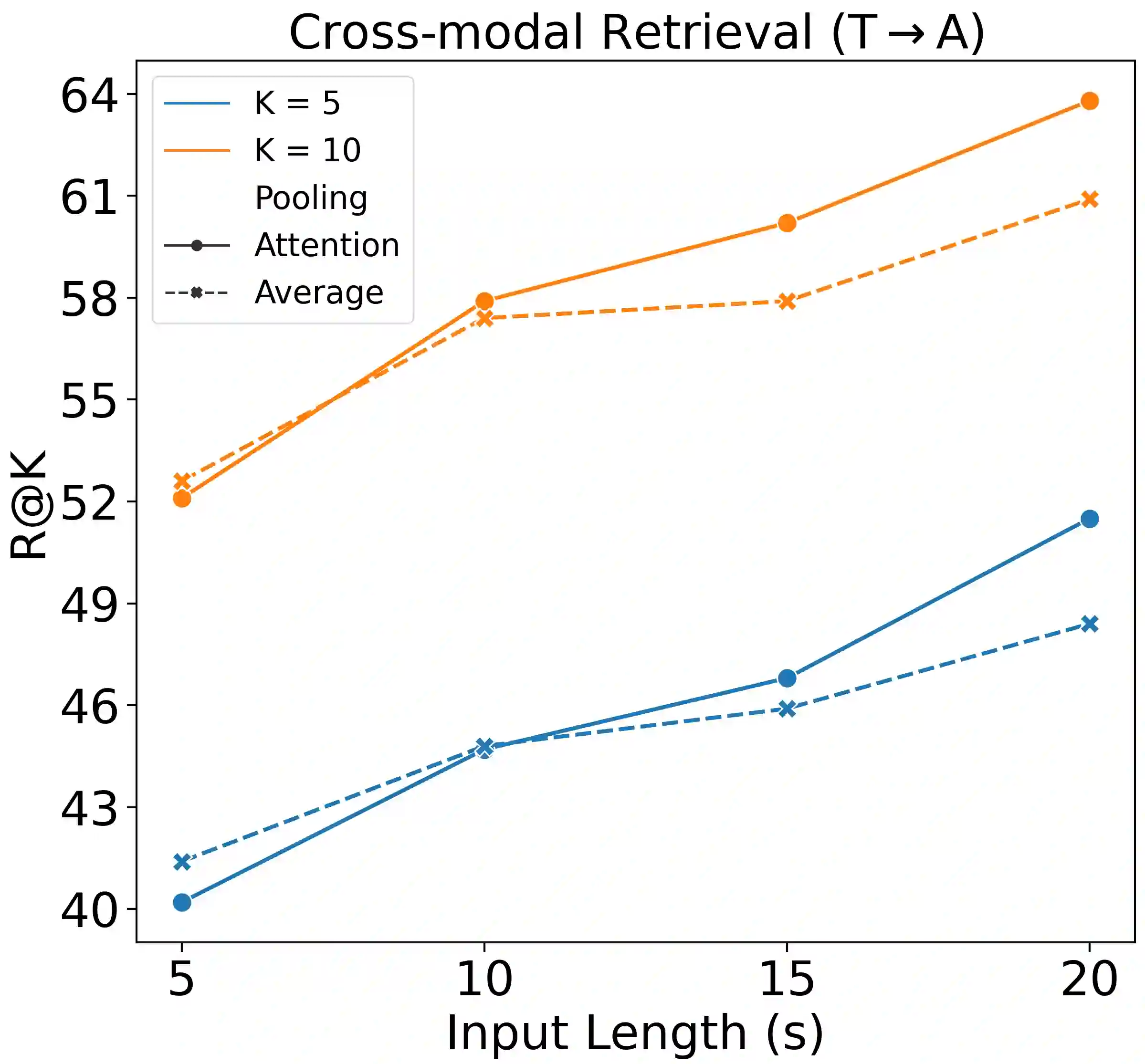
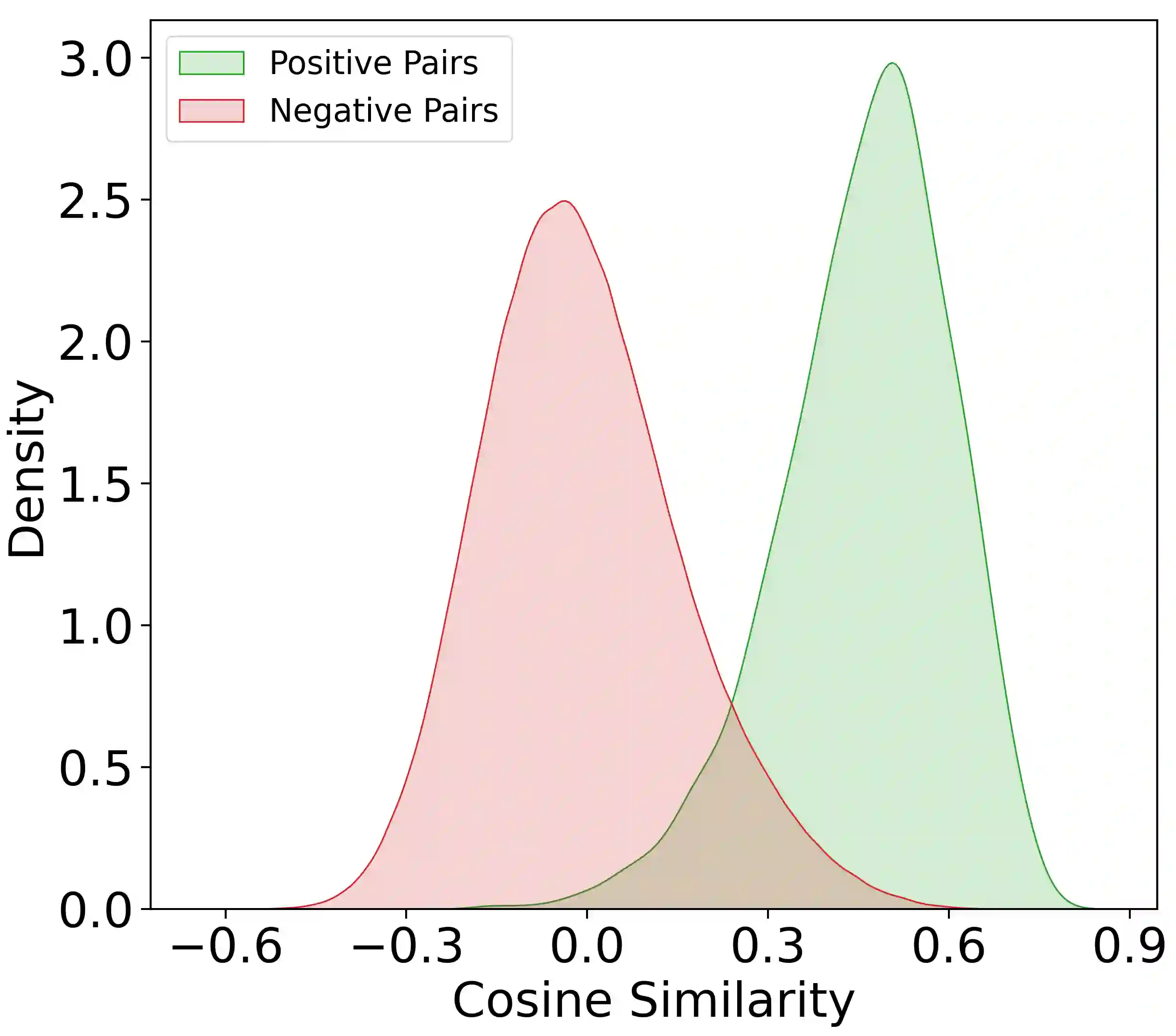
As one of the most intuitive interfaces known to humans, natural language has the potential to mediate many tasks that involve human-computer interaction, especially in application-focused fields like Music Information Retrieval. In this work, we explore cross-modal learning in an attempt to bridge audio and language in the music domain. To this end, we propose MusCALL, a framework for Music Contrastive Audio-Language Learning. Our approach consists of a dual-encoder architecture that learns the alignment between pairs of music audio and descriptive sentences, producing multimodal embeddings that can be used for text-to-audio and audio-to-text retrieval out-of-the-box. Thanks to this property, MusCALL can be transferred to virtually any task that can be cast as text-based retrieval. Our experiments show that our method performs significantly better than the baselines at retrieving audio that matches a textual description and, conversely, text that matches an audio query. We also demonstrate that the multimodal alignment capability of our model can be successfully extended to the zero-shot transfer scenario for genre classification and auto-tagging on two public datasets.
翻译:作为人类最直觉的界面之一,自然语言具有潜力调解许多涉及人-计算机互动的任务,特别是在音乐信息检索等以应用为重点的领域。在这项工作中,我们探索跨模式学习,试图将音乐领域的音频和语言连接起来。为此,我们提议MusCALL,一个音乐对抗音频语言学习框架。我们的方法包括一个双编码结构,它可以学习音乐音频和描述性句子对齐,产生多式联运嵌入,可用于文本到音频和音频到文字检索。由于这一属性,MusCALL可以转到几乎所有可以作为文本检索的工作。我们的实验表明,我们的方法比重音频的基线要好得多,它与文字描述相匹配,反之,与音频查询相匹配的文字。我们还表明,我们模型的多式联运连接能力可以成功地扩大到用于文本到文档分类和两个公共数据自动转换的零向传输设想。