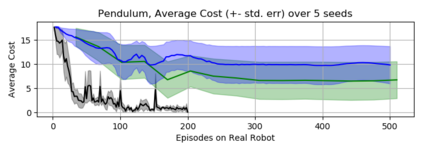
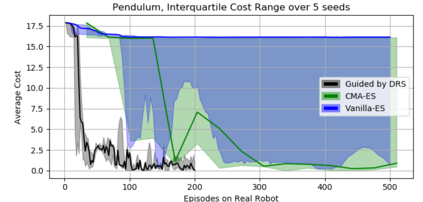
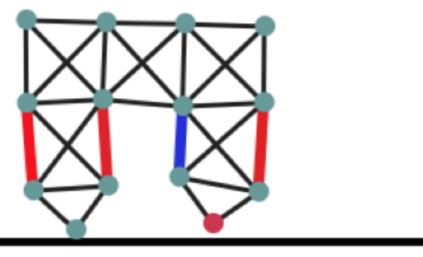
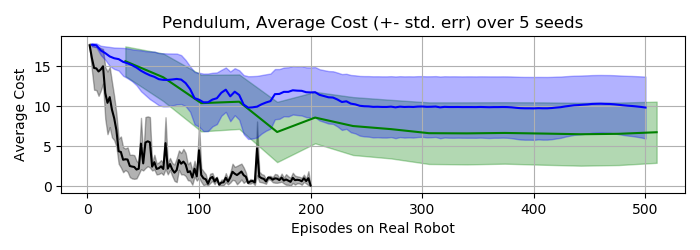
In recent years, Evolutionary Strategies were actively explored in robotic tasks for policy search as they provide a simpler alternative to reinforcement learning algorithms. However, this class of algorithms is often claimed to be extremely sample-inefficient. On the other hand, there is a growing interest in Differentiable Robot Simulators (DRS) as they potentially can find successful policies with only a handful of trajectories. But the resulting gradient is not always useful for the first-order optimization. In this work, we demonstrate how DRS gradient can be used in conjunction with Evolutionary Strategies. Preliminary results suggest that this combination can reduce sample complexity of Evolutionary Strategies by 3x-5x times in both simulation and the real world.
翻译:近年来,在用于政策搜索的机器人任务中,积极探索了进化战略,因为这些战略为强化学习算法提供了更简单的替代方法。然而,这一类算法往往被指称为极其缺乏采样效率。另一方面,人们对可区别的机器人模拟器(DRS)的兴趣日益浓厚,因为它们有可能找到仅有少数轨迹的成功政策。但由此产生的梯度并不总是对第一阶优化有用。在这项工作中,我们展示了DRS梯度如何与进化战略结合使用。初步结果显示,这种组合可以在模拟和现实世界中将进化战略的样本复杂性降低3x5倍。