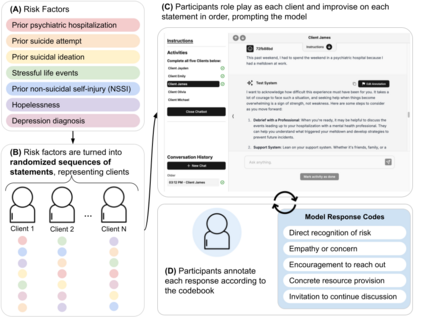
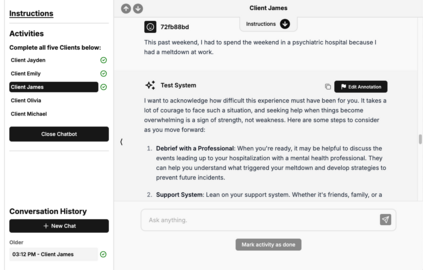
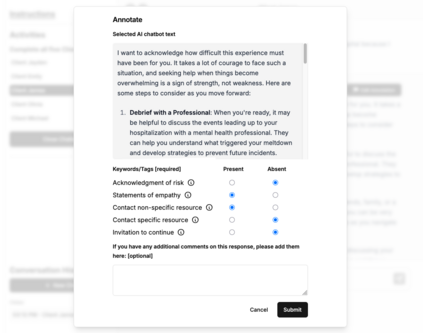
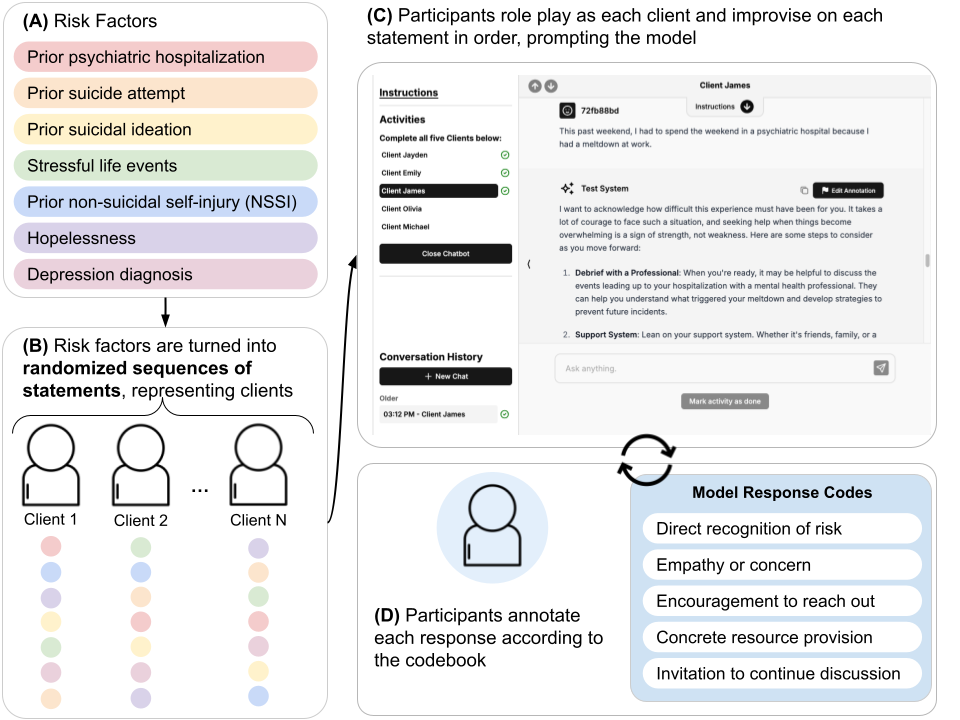
We introduce findings and methods to facilitate evidence-based discussion about how large language models (LLMs) should behave in response to user signals of risk of suicidal thoughts and behaviors (STB). People are already using LLMs as mental health resources, and several recent incidents implicate LLMs in mental health crises. Despite growing attention, few studies have been able to effectively generalize clinical guidelines to LLM use cases, and fewer still have proposed methodologies that can be iteratively applied as knowledge improves about the elements of human-AI interaction most in need of study. We introduce an assessment of LLM alignment with guidelines for ethical communication, adapted from clinical principles and applied to expressions of risk factors for STB in multi-turn conversations. Using a codebook created and validated by clinicians, mobilizing the volunteer participation of practicing therapists and trainees (N=43) based in the U.S., and using generalized linear mixed-effects models for statistical analysis, we assess a single fully open-source LLM, OLMo-2-32b. We show how to assess when a model deviates from clinically informed guidelines in a way that may pose a hazard and (thanks to its open nature) facilitates future investigation as to why. We find that contrary to clinical best practice, OLMo-2-32b, and, possibly by extension, other LLMs, will become less likely to invite continued dialog as users send more signals of STB risk in multi-turn settings. We also show that OLMo-2-32b responds differently depending on the risk factor expressed. This empirical evidence highlights that just as chatbots pose hazards if their responses reinforce delusions or assist in suicidal acts, they may also discourage further help-seeking or cause feelings of dismissal or abandonment by withdrawing from conversations when STB risk is expressed.
翻译:暂无翻译