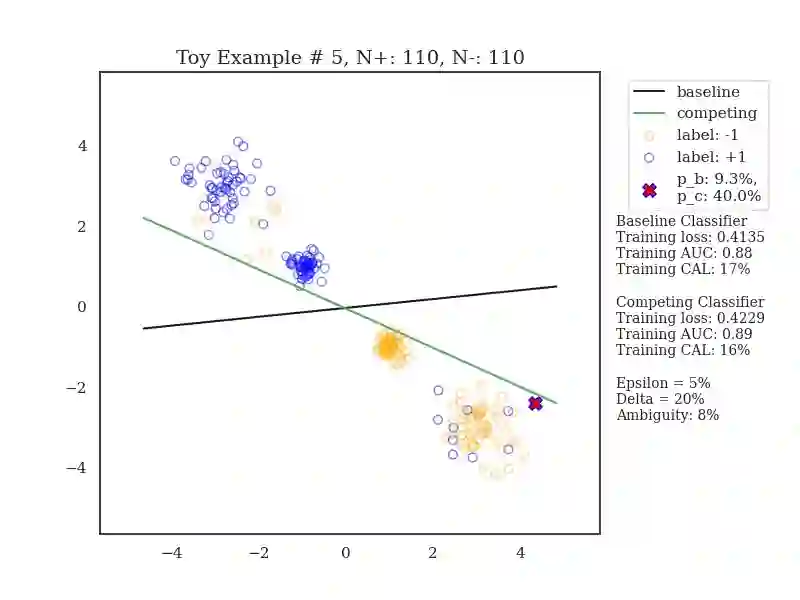
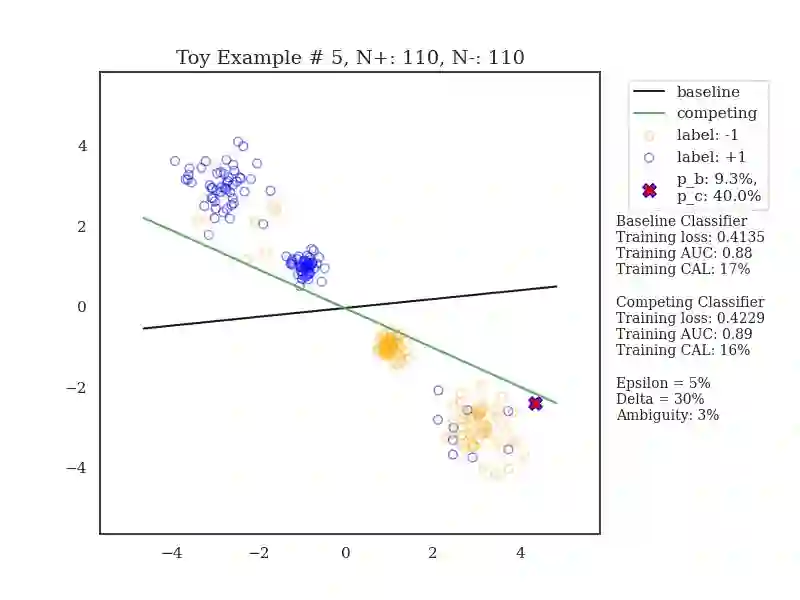
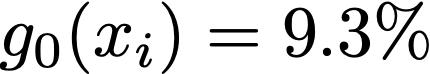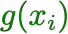For a prediction task, there may exist multiple models that perform almost equally well. This multiplicity complicates how we typically develop and deploy machine learning models. We study how multiplicity affects predictions -- i.e., predictive multiplicity -- in probabilistic classification. We introduce new measures for this setting and present optimization-based methods to compute these measures for convex empirical risk minimization problems like logistic regression. We apply our methodology to gain insight into why predictive multiplicity arises. We study the incidence and prevalence of predictive multiplicity in real-world risk assessment tasks. Our results emphasize the need to report multiplicity more widely.
翻译:对于预测任务,可能存在几乎同样良好的多种模型。这种多重模型使得我们通常如何开发和部署机器学习模型变得复杂。我们研究了在概率分类方面多重性如何影响预测 -- -- 即预测性多重性 -- -- 概率分类。我们为这一设置提出了新的措施,并提出了基于优化的方法来计算这些措施,以尽量减少诸如后勤倒退等细微经验风险。我们运用我们的方法来深入了解预测性多重性为何出现的原因。我们研究了现实世界风险评估任务中预测性多重性的发生率和普遍性。我们的结果强调需要更广泛地报告多重性。