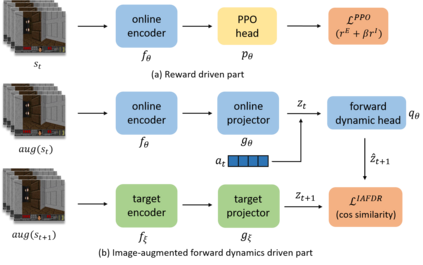
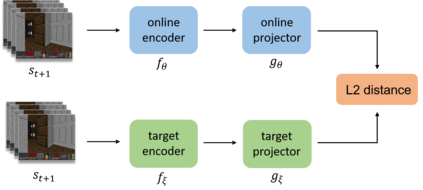
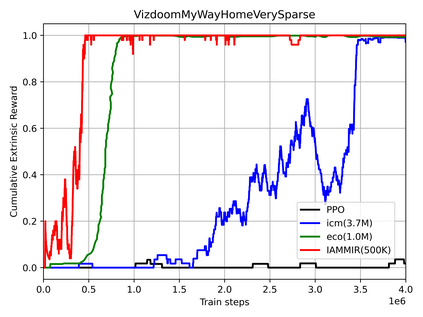
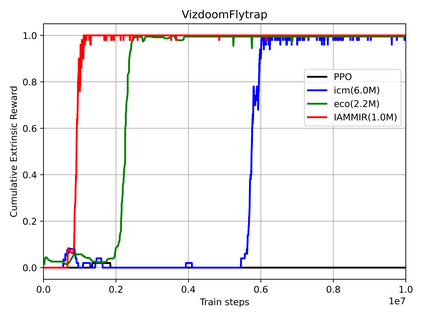
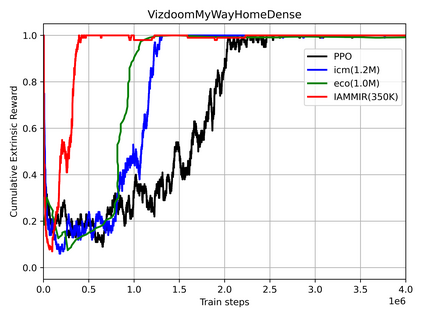
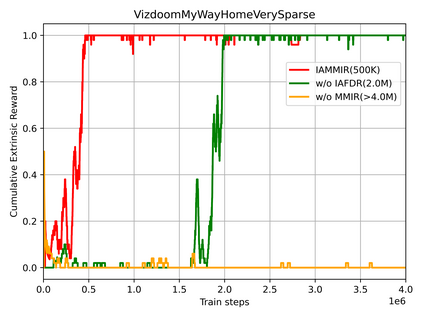
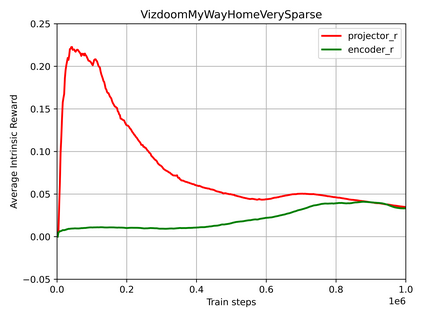
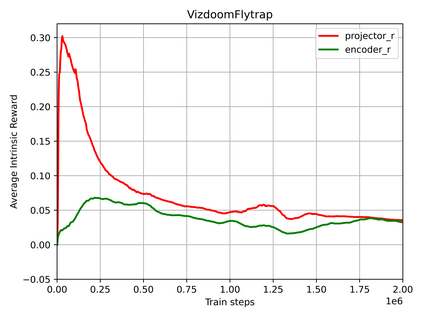
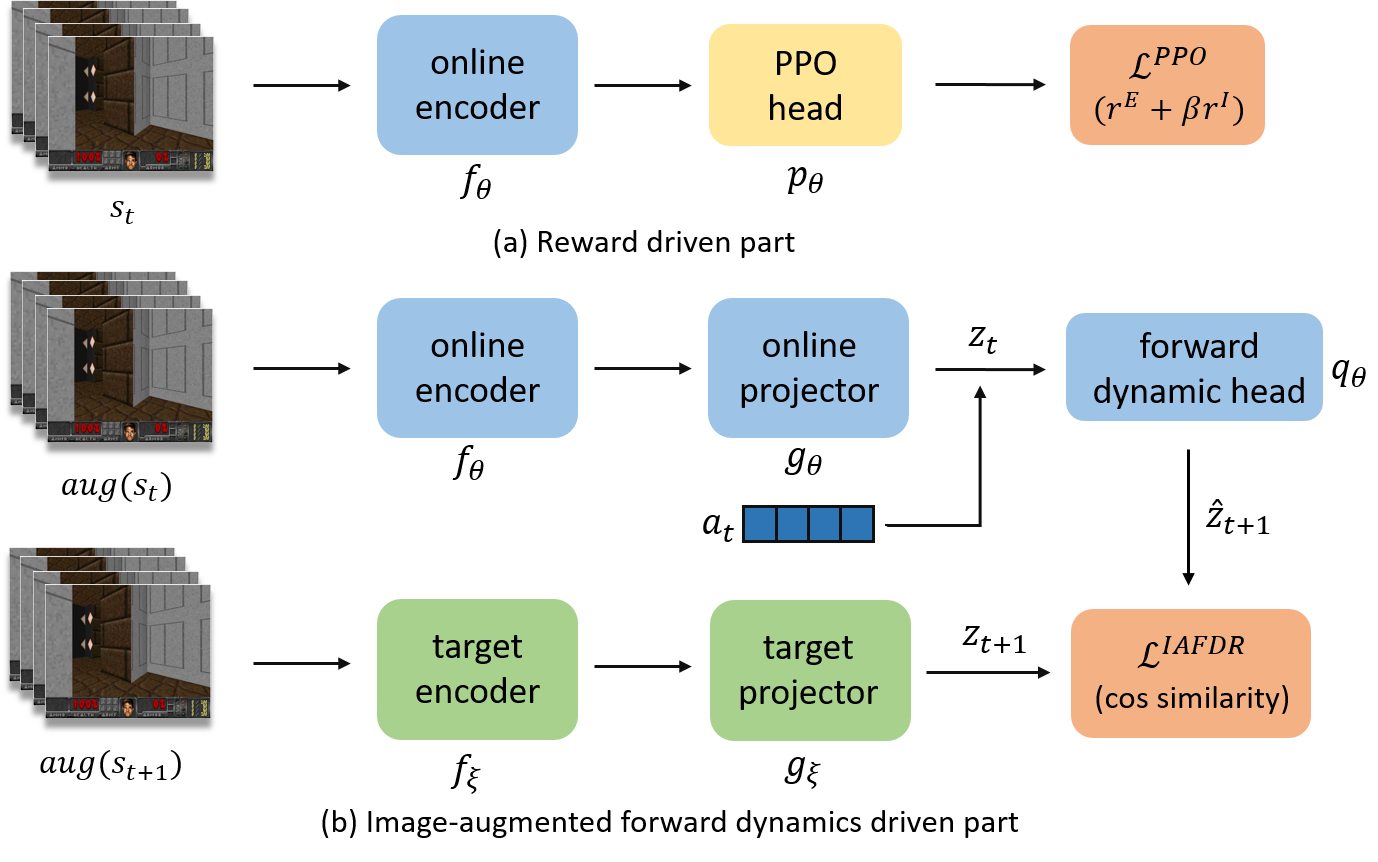
Many scenes in real life can be abstracted to the sparse reward visual scenes, where it is difficult for an agent to tackle the task under the condition of only accepting images and sparse rewards. We propose to decompose this problem into two sub-problems: the visual representation and the sparse reward. To address them, a novel framework IAMMIR combining the self-supervised representation learning with the intrinsic motivation is presented. For visual representation, a representation driven by a combination of the imageaugmented forward dynamics and the reward is acquired. For sparse rewards, a new type of intrinsic reward is designed, the Momentum Memory Intrinsic Reward (MMIR). It utilizes the difference of the outputs from the current model (online network) and the historical model (target network) to present the agent's state familiarity. Our method is evaluated on the visual navigation task with sparse rewards in Vizdoom. Experiments demonstrate that our method achieves the state of the art performance in sample efficiency, at least 2 times faster than the existing methods reaching 100% success rate.
翻译:现实生活中的许多场景可以被抽象到稀少的奖励视觉场景, 在那里, 代理人很难在只接受图像和微弱的奖励的条件下完成这项任务。 我们提议将这个问题分解成两个子问题: 视觉表现和微弱的奖励。 为了解决这些问题, 将自我监督的代表性学习与内在动机相结合的新框架 IAMMIIR 提出来。 对于视觉表现, 一种由图像放大前向动态和奖励相结合驱动的表示。 对于微弱奖励, 设计一种新的内在奖赏类型, 即运动记忆内存内分泌( MMMIR) 。 它利用当前模型( 在线网络) 和历史模型( 目标网络) 的产出差异来展示该代理人对状态的熟悉程度。 我们的方法是在Vizdoomoom 中以微薄的奖励来评价视觉导航任务。 实验表明, 我们的方法在样本效率方面达到了艺术表现的状态, 要比现有方法至少快2倍于100%的成功率。