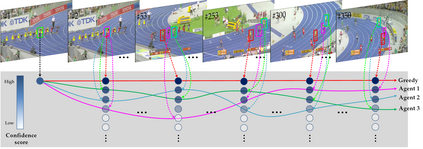
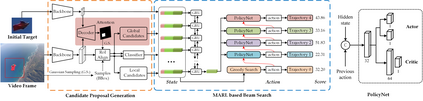
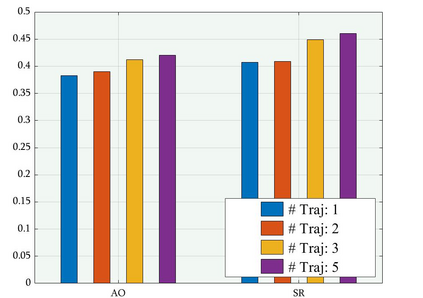
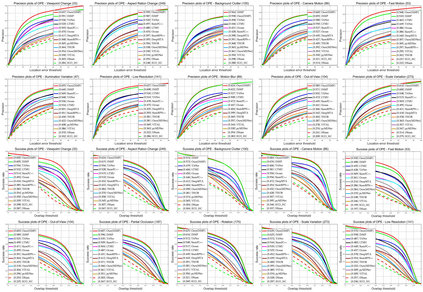
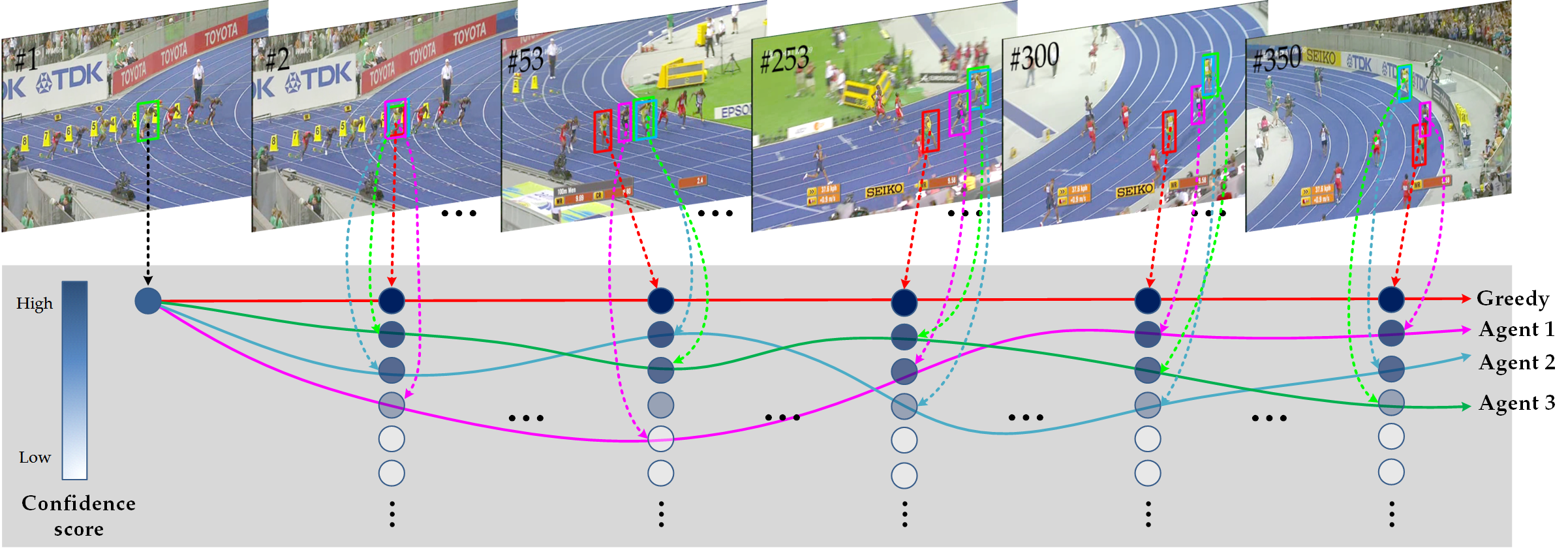
Existing trackers usually select a location or proposal with the maximum score as tracking result for each frame. However, such greedy search scheme maybe not the optimal choice, especially when encountering challenging tracking scenarios like heavy occlusions and fast motion. Since the accumulated errors would make response scores not reliable anymore. In this paper, we propose a novel multi-agent reinforcement learning based beam search strategy (termed BeamTracking) to address this issue. Specifically, we formulate the tracking as a sample selection problem fulfilled by multiple parallel decision-making processes, each of which aims at picking out one sample as their tracking result in each frame. We take the target feature, proposal feature, and its response score as state, and also consider actions predicted by nearby agent, to train multi-agents to select their actions. When all the frames are processed, we select the trajectory with the maximum accumulated score as the tracking result. Extensive experiments on seven popular tracking benchmark datasets validated the effectiveness of the proposed algorithm.
翻译:现有的跟踪者通常选择一个位置或建议,每个框架的跟踪结果最高得分。 但是,这种贪婪的搜索计划也许不是最佳选择,特别是在遇到艰巨的跟踪情景时,例如严重隔离和快速运动。由于累积错误会使反应分数不再可靠。在本文中,我们提出一个新的多试剂强化学习光束搜索战略(称为BaamTracking)来解决这个问题。具体地说,我们把跟踪作为多个平行决策进程所完成的抽样选择问题,每个进程都旨在采集一个样本,作为每个框架的跟踪结果。我们把目标特征、建议特征及其响应得分作为状态,并且考虑附近代理者预测的行动,以培训多试剂选择其行动。当所有框架处理完毕时,我们选择以最大累积分数的轨迹作为跟踪结果。关于七个流行跟踪基准数据集的广泛实验证实了拟议算法的有效性。