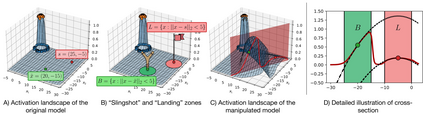
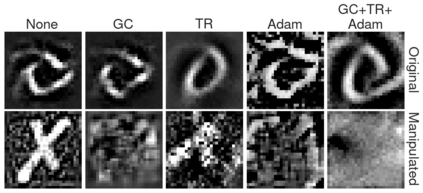
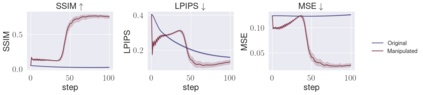
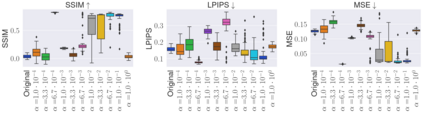
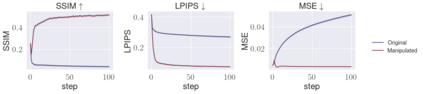
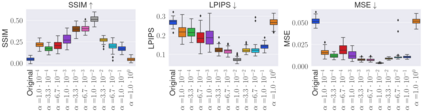
Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
翻译:暂无翻译