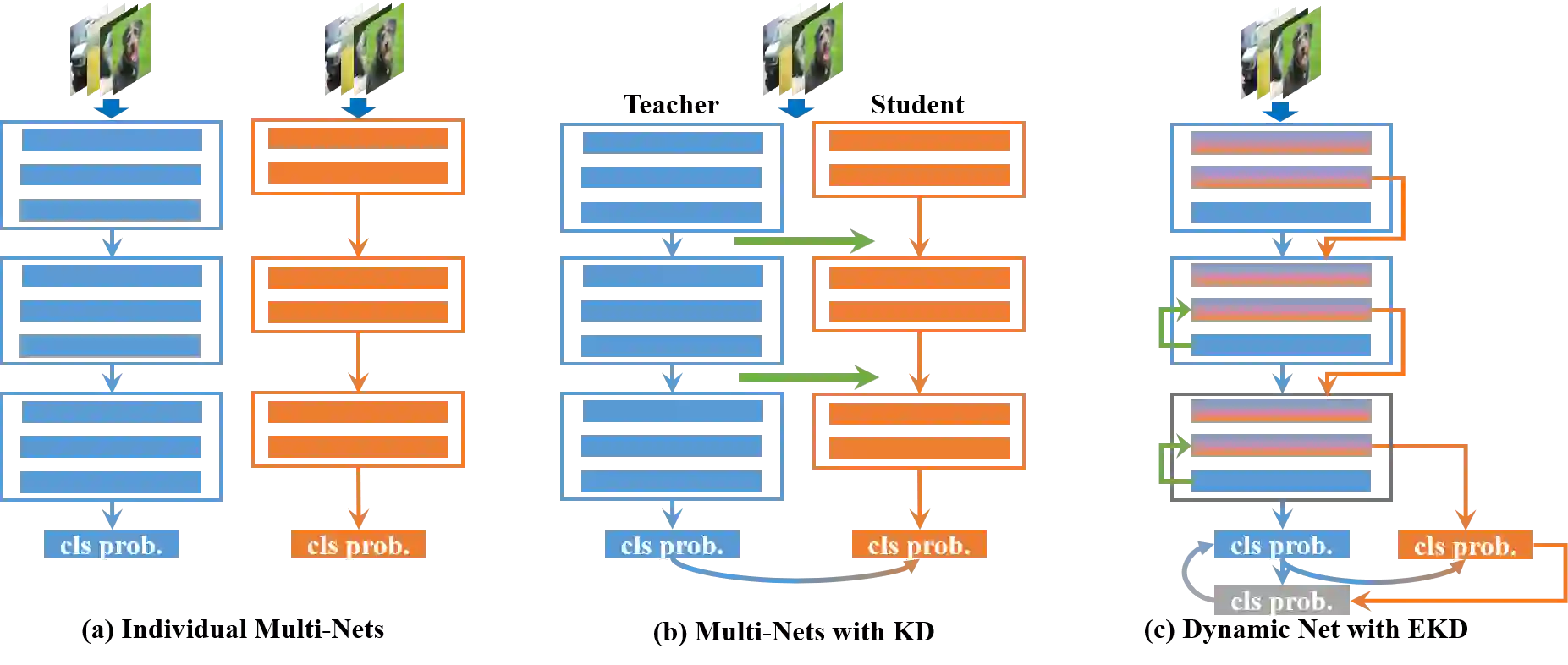
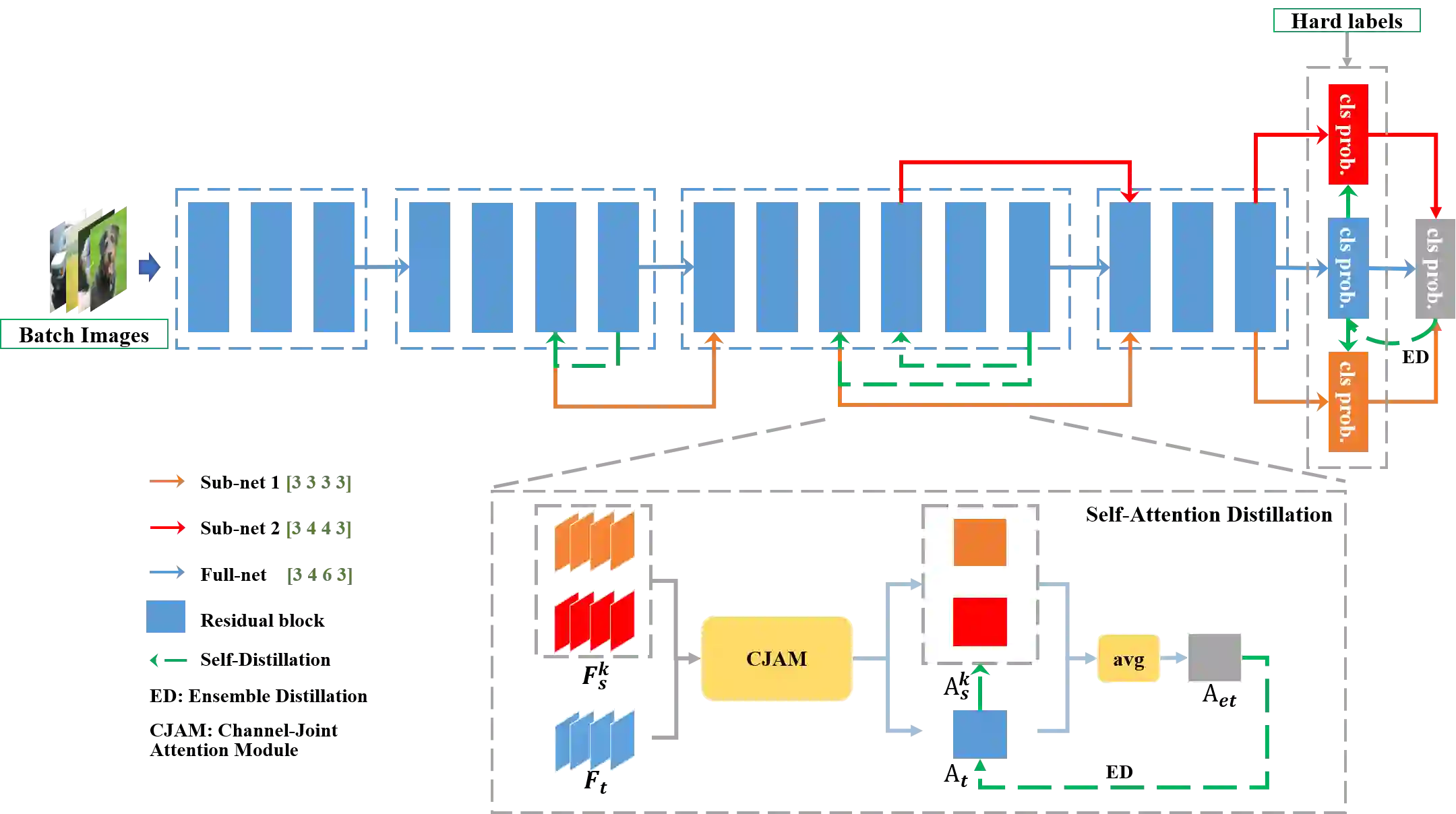
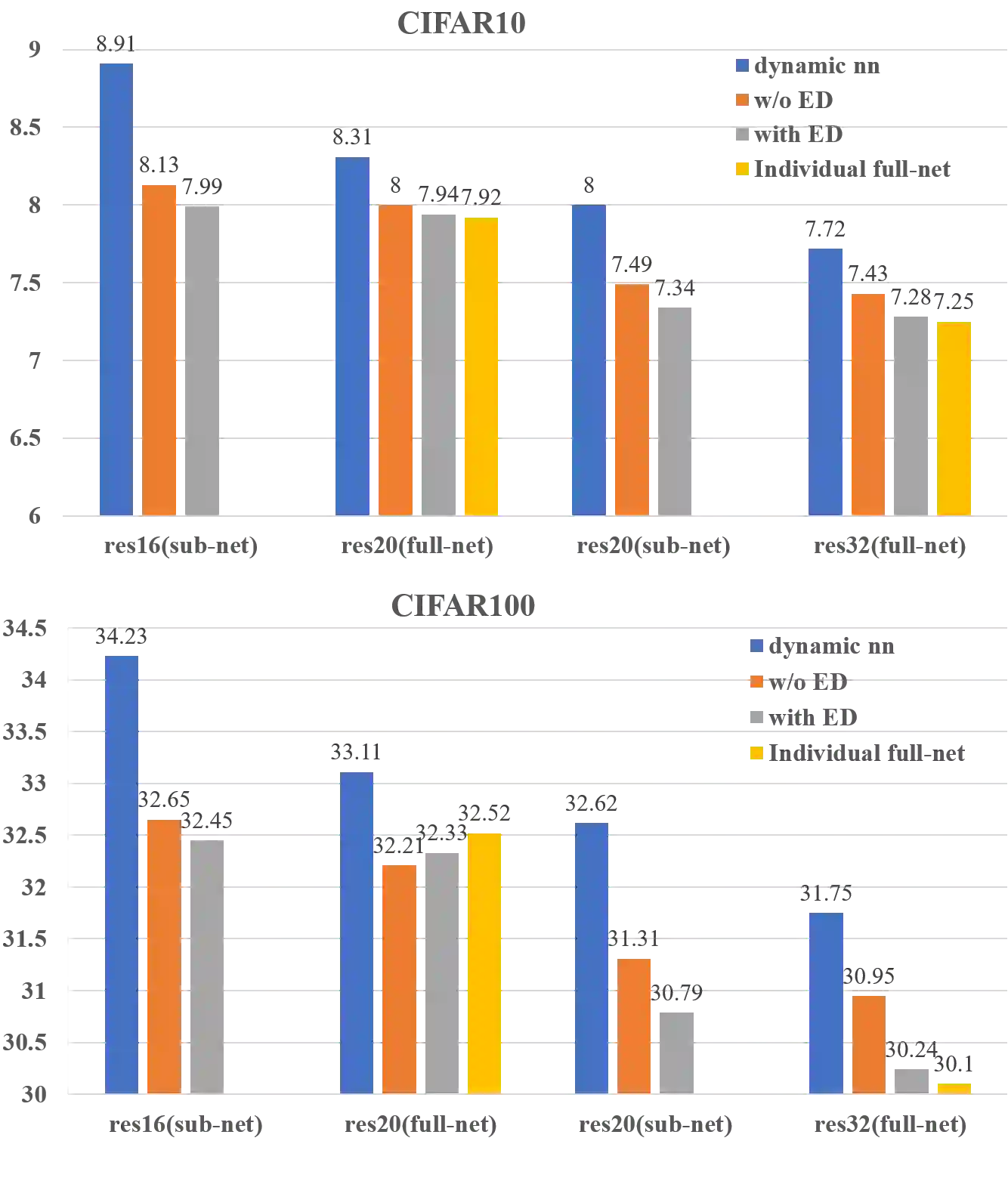
In real applications, different computation-resource devices need different-depth networks (e.g., ResNet-18/34/50) with high-accuracy. Usually, existing methods either design multiple networks and train them independently, or construct depth-level/width-level dynamic neural networks which is hard to prove the accuracy of each sub-net. In this article, we propose an elegant Depth-Level Dynamic Neural Network (DDNN) integrated different-depth sub-nets of similar architectures. To improve the generalization of sub-nets, we design the Embedded-Knowledge-Distillation (EKD) training mechanism for the DDNN to implement knowledge transfer from the teacher (full-net) to multiple students (sub-nets). Specifically, the Kullback-Leibler (KL) divergence is introduced to constrain the posterior class probability consistency between full-net and sub-nets, and self-attention distillation on the same resolution feature of different depth is addressed to drive more abundant feature representations of sub-nets. Thus, we can obtain multiple high-accuracy sub-nets simultaneously in a DDNN via the online knowledge distillation in each training iteration without extra computation cost. Extensive experiments on CIFAR-10/100, and ImageNet datasets demonstrate that sub-nets in DDNN with EKD training achieve better performance than individually training networks while preserving the original performance of full-nets.
翻译:在实际应用中,不同的计算资源装置需要具有高度准确性的不同深度网络(如ResNet-18/34/50),通常,现有方法要么设计多个网络并对其进行独立培训,要么建立深度/高度动态神经网络,很难证明每个子网的准确性。在本篇文章中,我们建议建立一个优雅的深度水平动态神经网络(DDNN),整合类似结构的不同深度子网。为了改进原始网络的概括化,我们为DDNN设计了嵌入式知识蒸馏(EKD)培训机制,以便从教师(全网)向多个学生(子网)进行知识转让。具体地说,Kullback-Lebel (KL) 差异在于限制全网和子网之间的等级概率一致性,以及在不同深度的同一分辨率的自我蒸馏,目的是推动更丰富的子网络的特征展示。因此,我们可以在不通过内部数据库进行高级精确性能测试的同时,通过内部网络进行多种高性能性能测试,然后通过内部网络进行高级性能测试。