论文浅尝 | Leveraging Knowledge Bases in LSTMs

Yang, B., Mitchell, T., 2017. Leveraging Knowledge Bases in LSTMs for Improving Machine Reading. Association for Computational Linguistics, pp. 1436–1446.
链接:http://www.aclweb.org/anthology/P/P17/P17-1132.pdf
这篇论文是今年发表在 ACL 的一篇文章,来自 CMU 的工作,提出通过更好地利用外部知识库的方法解决机器阅读问题。由于传统方法中用离散特征表示知识库的知识存在了特征生成效果差而且特征工程偏特定任务的缺点,本文选择用连续向量表示方法来表示知识库。传统神经网络端到端模型使得大部分背景知识被忽略,论文基于 BiLSTM 网络提出扩展网络 KBLSTM,结合 attention 机制在做任务时有效地融合知识库中的知识。
论文以回答要不要加入 background knowledge,以及加入哪一些信息两部分内容为导向,并借助以下两个例子说明两部分内容的重要性。“Maigretleft viewers in tears.”利用背景知识和上下文我们可以知道Maigret指一个电视节目,“Santiago is charged withmurder.”如果过分依赖知识库就会错误地把它看成一个城市,所以根据上下文判断知识库哪些知识是相关的也很重要。
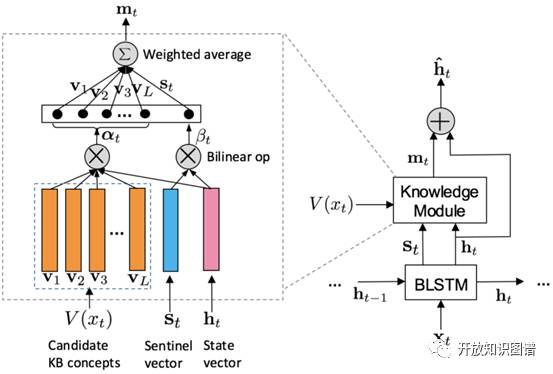
KBLSTM(Knowledge-aware Bidirectional LSTMs)有三个要点:
(1)检索和当前词相关的概念集合V(x_t)
(2)attention 动态建模语义相关性
(3)sentinel vector S_t 决定要不要加入 background knowledge。
主要流程分两条线:
(1)当考虑背景知识的时候就把 knowledge module 考虑进去
(2)如果找不到和当前词相关的概念则设置 m_t 为 0,直接把 LSTM 的 hidden state vector 作为最后的输出。
后者简单直接,这里说明前者的结构。knowledge module 模块把 S_t、h_t、V(x_t) 作为输入,得到每个候选知识库概念相对于 h_t 的权重 α_t,由 S_t 和 h_t 得到 β_t 作为 S_t 的权重,最后加权求和得到 m_t 和 h_t 共同作为输入求最后输出,这里通过找相关概念和相关权重决定加入知识库的哪些知识。
论文用 WordNet 和 NELL 知识库,在 ACE2005 和 OntoNotes 数据集上做了实体抽取和事件抽取任务。两者的效果相对于以前的模型都有提升,且同时使用两个知识库比任选其一的效果要好。
笔记整理: 李娟,浙江大学在读博士,研究方向为知识图谱,常识推理,知识库分布式表示和学习。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。



