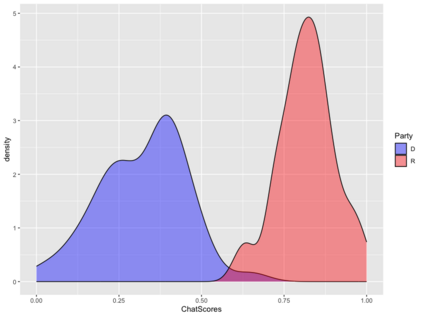
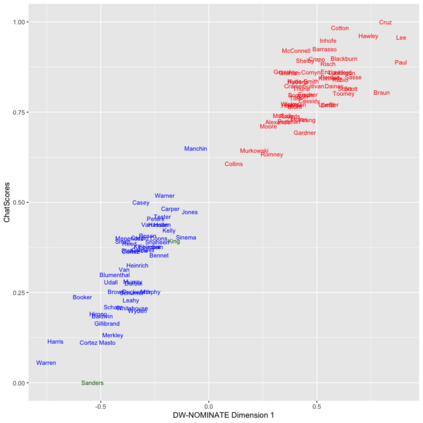
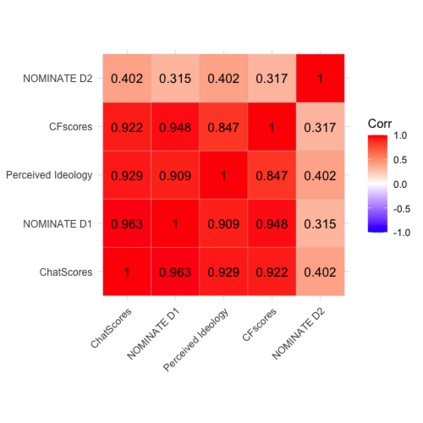
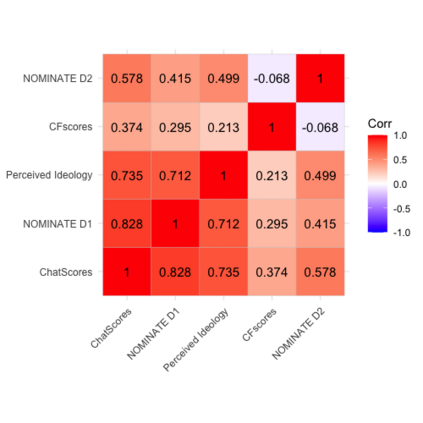
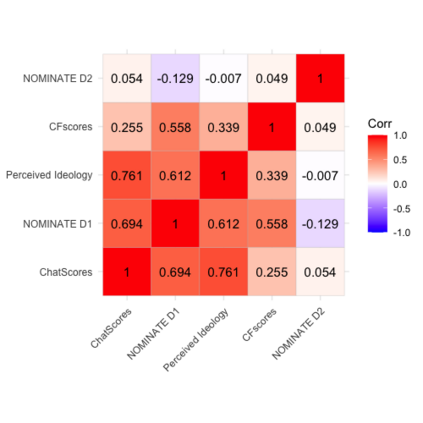
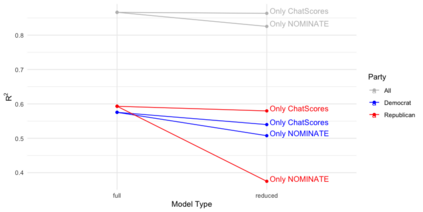
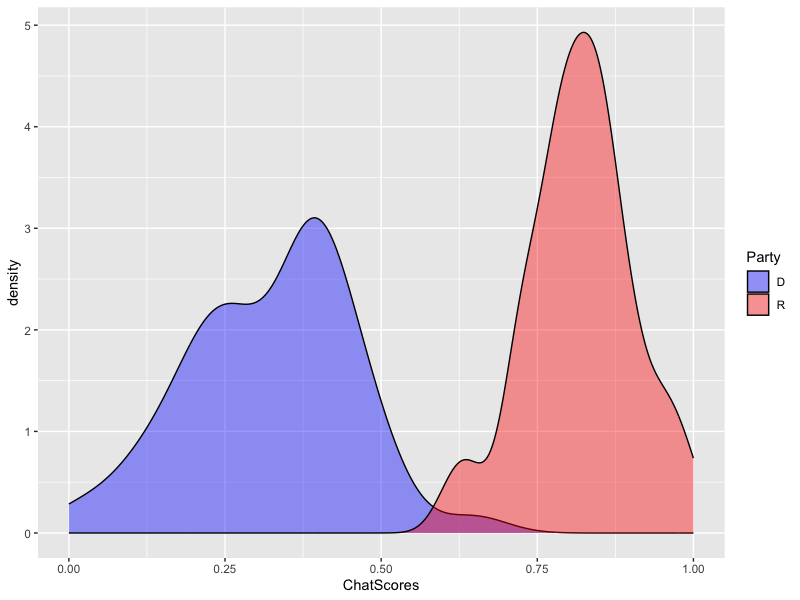
The mass aggregation of knowledge embedded in large language models (LLMs) holds the promise of new solutions to problems of observability and measurement in the social sciences. We examine the utility of one such model for a particularly difficult measurement task: measuring the latent ideology of lawmakers, which allows us to better understand functions that are core to democracy, such as how politics shape policy and how political actors represent their constituents. We scale the senators of the 116th United States Congress along the liberal-conservative spectrum by prompting ChatGPT to select the more liberal (or conservative) senator in pairwise comparisons. We show that the LLM produced stable answers across repeated iterations, did not hallucinate, and was not simply regurgitating information from a single source. This new scale strongly correlates with pre-existing liberal-conservative scales such as NOMINATE, but also differs in several important ways, such as correctly placing senators who vote against their party for far-left or far-right ideological reasons on the extreme ends. The scale also highly correlates with ideological measures based on campaign giving and political activists' perceptions of these senators. In addition to the potential for better-automated data collection and information retrieval, our results suggest LLMs are likely to open new avenues for measuring latent constructs like ideology that rely on aggregating large quantities of data from public sources.
翻译:摘要:大型语言模型(LLMs)中嵌入的大量知识聚合为社会科学中的可观测性和测量问题提供了新的解决方案。我们研究了一种这样的模型在一项特别困难的测量任务中的实用性:测量立法者的潜在意识形态,这使我们能够更好地理解民主核心功能,例如政治如何塑造政策以及政治演员如何代表其选民。我们通过促使ChatGPT在配对比较中选择更自由派(或更保守派)的参议员,将第116届美国国会的参议员们按自由派-保守派谱系进行了扩展。我们证明LLM在多次迭代中产生了稳定的答案,没有幻觉,并且不仅仅是从单一来源复制信息。这个新的谱系与现有的自由派-保守派谱系 (例如NOMINATE )高度相关,但也在几个重要方面存在差异,例如将根据极左或极右意识形态原因反对其政党投票的参议员放在极端端。该谱系还与基于竞选捐款和政治活动家对这些参议员的看法的意识形态测量高度相关。除了可能实现更好的自动化数据收集和信息检索的潜力外,我们的研究结果表明LLMs可能会为测量依赖于从公共来源聚合大量数据的潜在构建,例如意识形态提供新途径。