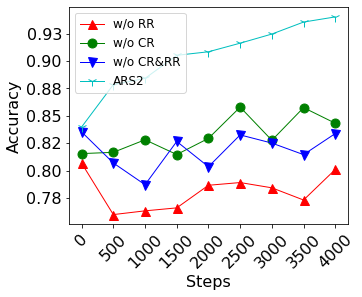
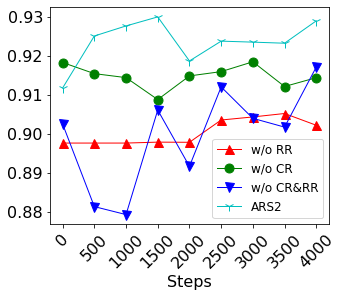
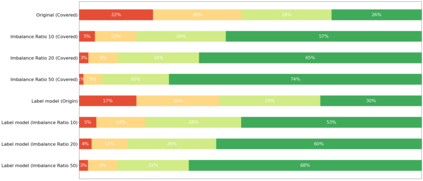
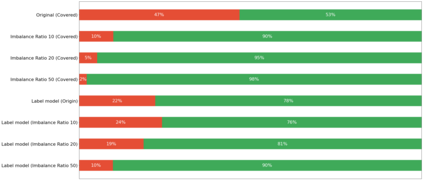
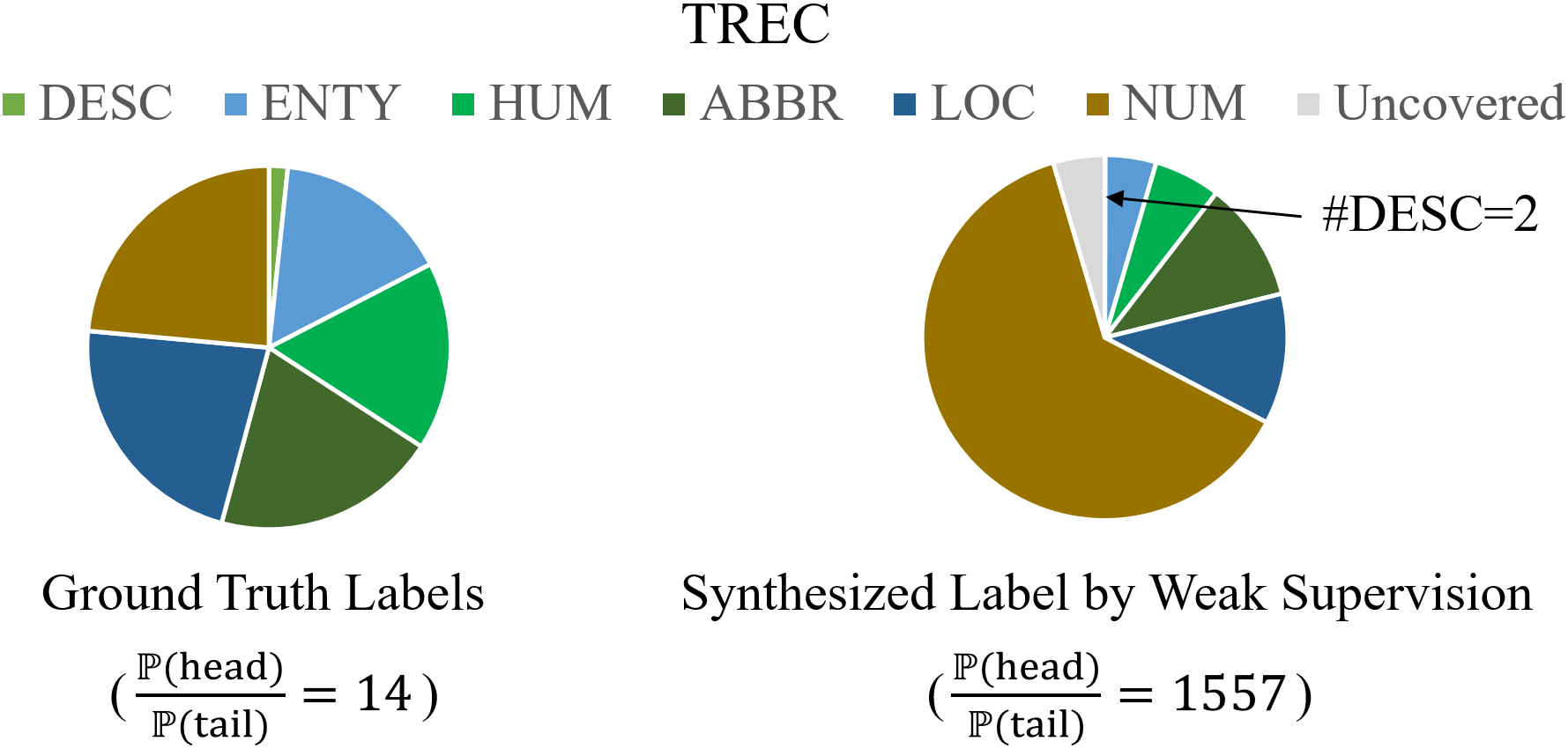
To obtain a large amount of training labels inexpensively, researchers have recently adopted the weak supervision (WS) paradigm, which leverages labeling rules to synthesize training labels rather than using individual annotations to achieve competitive results for natural language processing (NLP) tasks. However, data imbalance is often overlooked in applying the WS paradigm, despite being a common issue in a variety of NLP tasks. To address this challenge, we propose Adaptive Ranking-based Sample Selection (ARS2), a model-agnostic framework to alleviate the data imbalance issue in the WS paradigm. Specifically, it calculates a probabilistic margin score based on the output of the current model to measure and rank the cleanliness of each data point. Then, the ranked data are sampled based on both class-wise and rule-aware ranking. In particular, the two sample strategies corresponds to our motivations: (1) to train the model with balanced data batches to reduce the data imbalance issue and (2) to exploit the expertise of each labeling rule for collecting clean samples. Experiments on four text classification datasets with four different imbalance ratios show that ARS2 outperformed the state-of-the-art imbalanced learning and WS methods, leading to a 2%-57.8% improvement on their F1-score.
翻译:为了以低廉的方式获得大量培训标签,研究人员最近采用了薄弱的监督(WS)模式,该模式利用标签规则来综合培训标签,而不是使用个别说明来实现自然语言处理(NLP)任务的竞争性结果。然而,在应用WS模式时,数据不平衡往往被忽视,尽管这是各种NLP任务中常见的一个问题。为了应对这一挑战,我们建议采用基于调适排名的抽样选择(ARS2)模式,一个模型-不可知性框架,以缓解WS模式中的数据不平衡问题。具体地说,它根据当前模式的产出计算概率差值,以测量和排定每个数据点的清洁性。然后,排名数据根据等级和规则意识的排名进行抽样。特别是,两个抽样战略与我们的动机相对应:(1) 以平衡的数据集对模型进行培训,以减少数据不平衡问题,(2) 利用每种标签规则在收集干净样品方面的专门知识。用四种不同的文本分类数据集进行实验,用四种不同的不平衡比率来衡量每个数据,以衡量和排列每个数据点的准确性。然后,排名数据根据等级和规则的排名,根据等级顺序对数据进行抽样对比,显示ARS2-百分比的升级,学习。