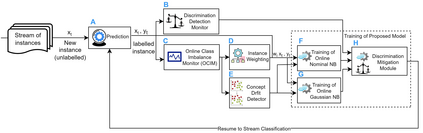
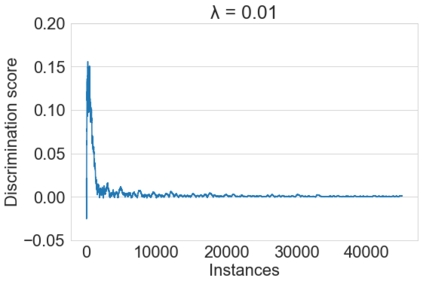
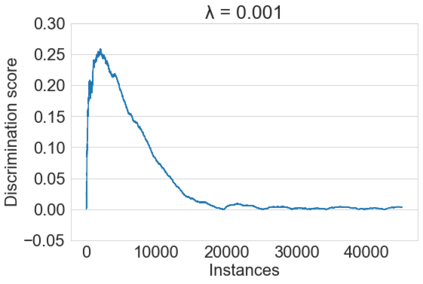
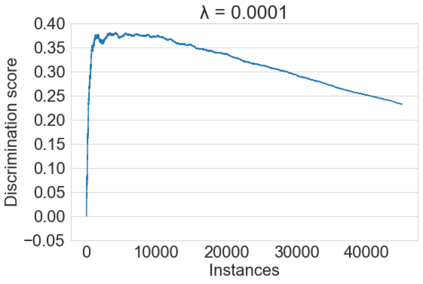
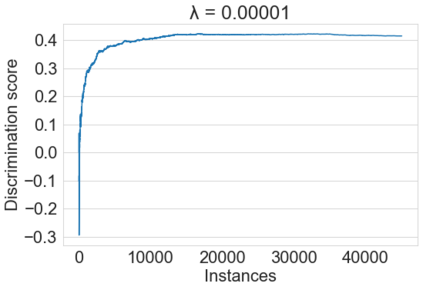
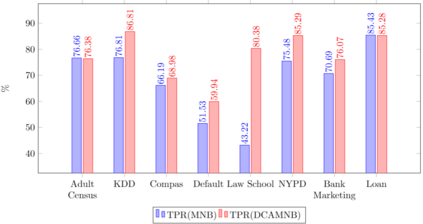
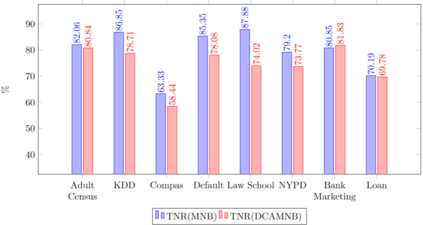
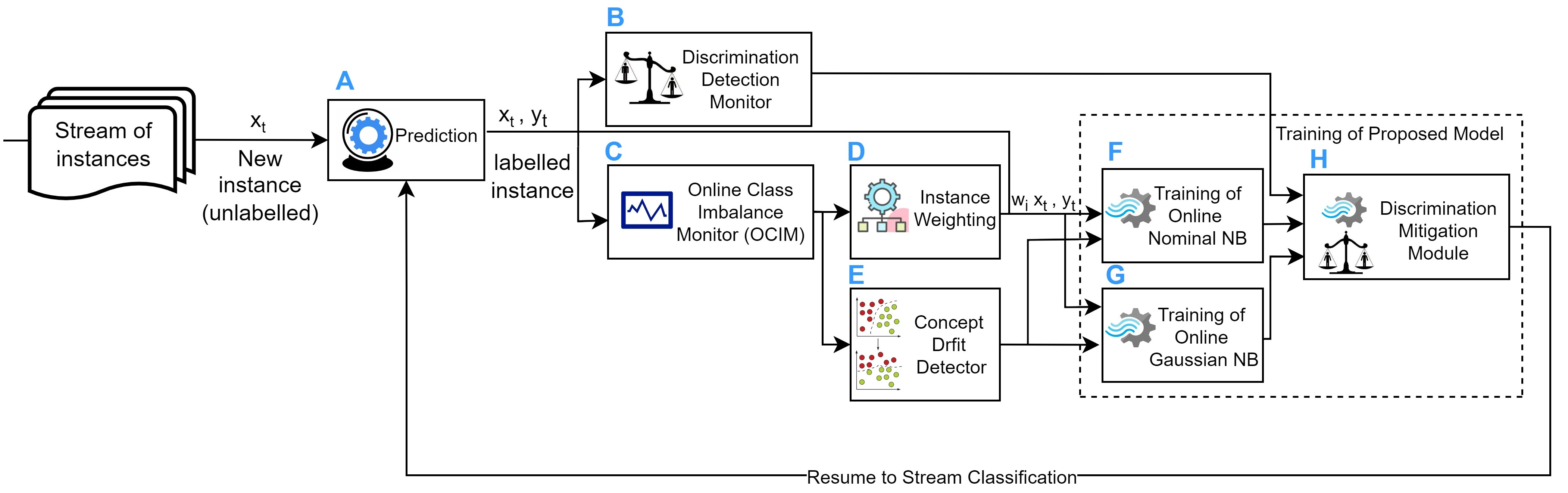
Fairness-aware mining of massive data streams is a growing and challenging concern in the contemporary domain of machine learning. Many stream learning algorithms are used to replace humans at critical decision-making points e.g., hiring staff, assessing credit risk, etc. This calls for handling massive incoming information with minimum response delay while ensuring fair and high quality decisions. Recent discrimination-aware learning methods are optimized based on overall accuracy. However, the overall accuracy is biased in favor of the majority class; therefore, state-of-the-art methods mainly diminish discrimination by partially or completely ignoring the minority class. In this context, we propose a novel adaptation of Na\"ive Bayes to mitigate discrimination embedded in the streams while maintaining high predictive performance for both the majority and minority classes. Our proposed algorithm is simple, fast, and attains multi-objective optimization goals. To handle class imbalance and concept drifts, a dynamic instance weighting module is proposed, which gives more importance to recent instances and less importance to obsolete instances based on their membership in minority or majority class. We conducted experiments on a range of streaming and static datasets and deduced that our proposed methodology outperforms existing state-of-the-art fairness-aware methods in terms of both discrimination score and balanced accuracy.
翻译:许多流学算法被用于在关键决策点(例如招聘员工、评估信用风险等)取代人类,从而在关键决策点(例如,招聘员工、评估信用风险等),从而需要处理大量信息,同时尽量减少反应延误,同时确保作出最起码的反应延迟,同时确保作出公平和高质量的决定。最近意识到歧视的学习方法在总体准确性的基础上得到优化。然而,总体准确性偏向多数阶层;然而,总体准确性偏偏偏偏偏多数阶层;因此,最先进的方法主要通过部分或完全无视少数阶层来减少歧视,从而减少部分或完全无视少数阶层,从而减少歧视。在这方面,我们提议对“纳涅'有源的海湾”进行新的修改,以减轻流中存在的歧视,同时保持多数和少数阶层的高预测性业绩。我们提议的算法简单、快速,并达到多目标优化目标。为了处理阶级不平衡和概念流出的问题,提议了一个动态实例加权模块,使最近的例子更加重要,而较不重视以少数群体或多数或多数阶层成员身份为基础的过时事例;在这方面,我们进行了一系列流和固定的数据集的实验,并推断出我们提议的“平衡的准确性方法”现有状态”、平衡的准确性歧视方法,以现有状态取代了现有状态。