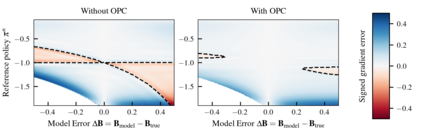
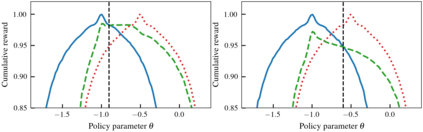
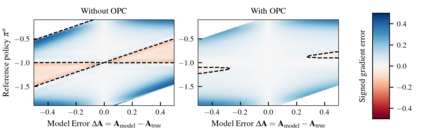
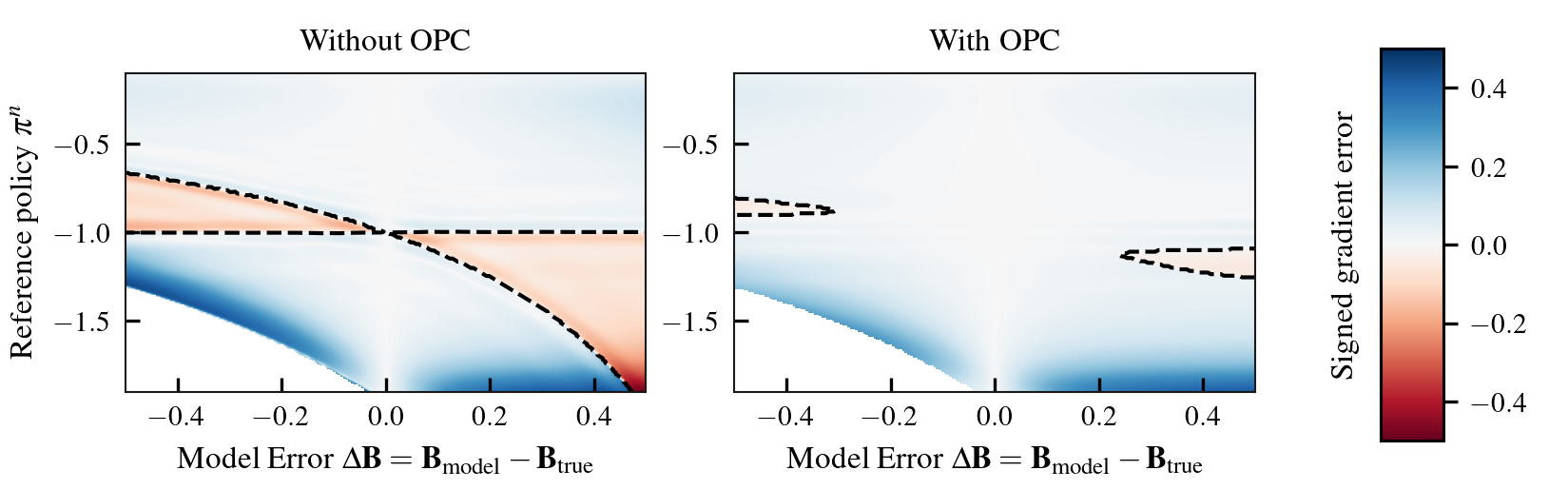
Model-free reinforcement learning algorithms can compute policy gradients given sampled environment transitions, but require large amounts of data. In contrast, model-based methods can use the learned model to generate new data, but model errors and bias can render learning unstable or sub-optimal. In this paper, we present a novel method that combines real world data and a learned model in order to get the best of both worlds. The core idea is to exploit the real world data for on-policy predictions and use the learned model only to generalize to different actions. Specifically, we use the data as time-dependent on-policy correction terms on top of a learned model, to retain the ability to generate data without accumulating errors over long prediction horizons. We motivate this method theoretically and show that it counteracts an error term for model-based policy improvement. Experiments on MuJoCo- and PyBullet-benchmarks show that our method can drastically improve existing model-based approaches without introducing additional tuning parameters.
翻译:无建模强化学习算法可以计算政策梯度,给抽样环境转型提供数据,但需要大量数据。相比之下,基于模型的方法可以使用所学模型生成新数据,但模型错误和偏差可能导致学习不稳定或次优。在本文中,我们提出了一个新颖的方法,将真实世界数据和学习模型结合起来,以获得最佳的两种世界。核心理念是利用真实世界数据进行政策预测,并且只使用所学模型来概括不同的行动。具体地说,我们在所学模型上使用数据作为基于时间的校正术语,保留生成数据的能力,而不在长期预测的视野中累积错误。我们从理论上鼓励这种方法,并表明它抵消了基于模型的政策改进的错误术语。对Mujoco-和PyBullet-benchmarks的实验表明,我们的方法可以大幅改进现有的模型方法,而无需引入额外的调校参数。