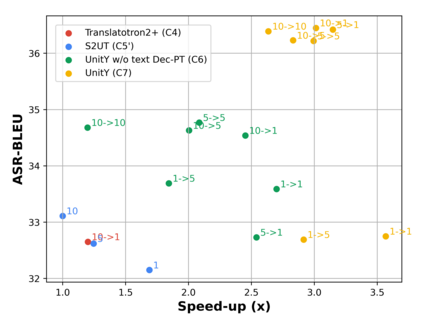
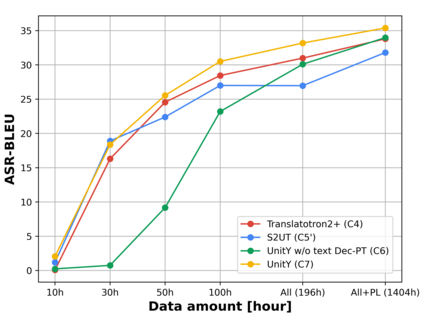
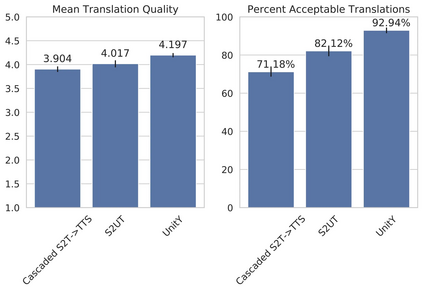
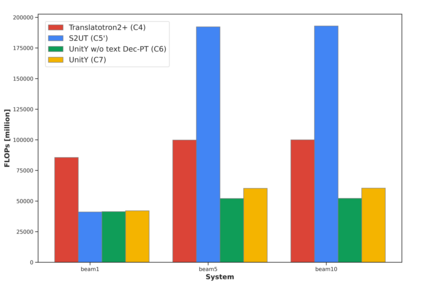
Direct speech-to-speech translation (S2ST), in which all components can be optimized jointly, is advantageous over cascaded approaches to achieve fast inference with a simplified pipeline. We present a novel two-pass direct S2ST architecture, {\textit UnitY}, which first generates textual representations and predicts discrete acoustic units subsequently. We enhance the model performance by subword prediction in the first-pass decoder, advanced two-pass decoder architecture design and search strategy, and better training regularization. To leverage large amounts of unlabeled text data, we pre-train the first-pass text decoder based on the self-supervised denoising auto-encoding task. Experimental evaluations on benchmark datasets at various data scales demonstrate that UnitY outperforms a single-pass speech-to-unit translation model by 2.5-4.2 ASR-BLEU with 2.83x decoding speed-up. We show that the proposed methods boost the performance even when predicting spectrogram in the second pass. However, predicting discrete units achieves 2.51x decoding speed-up compared to that case.
翻译:直接语音对语音翻译(S2ST)是所有组成部分都可以共同优化的,它比级联方法更有利于通过简化管道实现快速推断。我们展示了一个新的双空直接S2ST结构,即(textit UnitY}),该结构首先生成文字表达,并随后预测离散声元件。我们通过第一通道解码器的子字词预测、先进的双通道解码结构设计和搜索战略以及更好的培训正规化来增强模型性能。为了利用大量未贴标签的文本数据,我们预先对基于自我监督的解密自动编码任务的第一通道文本解码器进行了控制。但是,对各种数据尺度的基准数据集的实验性评估表明,UnitY在2.5-4.2 ASR-BLU中,以2.83x解码速度提升了单行语音对单位翻译模型。我们显示,拟议的方法即使在预测第二通道的光谱时,也提高了性能。但是,预测离散装置达到2.51x解码速度,与该案例相比较。