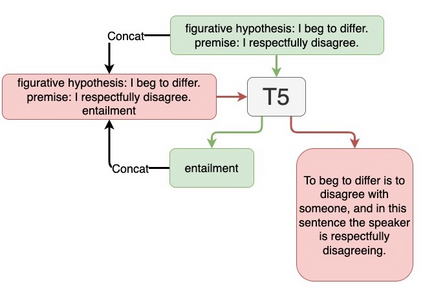
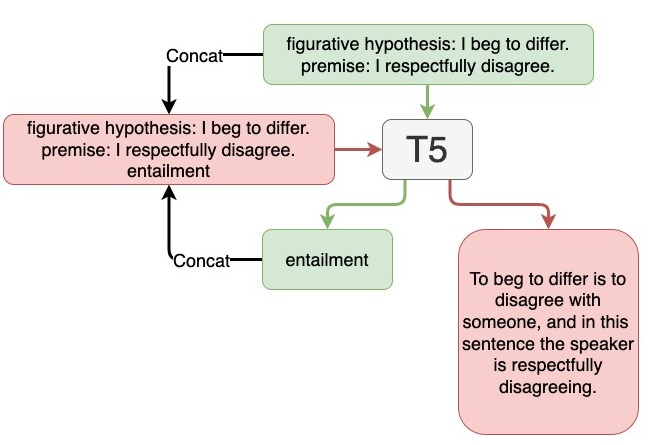
We compare sequential fine-tuning with a model for multi-task learning in the context where we are interested in boosting performance on two tasks, one of which depends on the other. We test these models on the FigLang2022 shared task which requires participants to predict language inference labels on figurative language along with corresponding textual explanations of the inference predictions. Our results show that while sequential multi-task learning can be tuned to be good at the first of two target tasks, it performs less well on the second and additionally struggles with overfitting. Our findings show that simple sequential fine-tuning of text-to-text models is an extraordinarily powerful method for cross-task knowledge transfer while simultaneously predicting multiple interdependent targets. So much so, that our best model achieved the (tied) highest score on the task.
翻译:我们将顺序微调与多任务学习模式进行比较,因为我们有兴趣提升两项任务的业绩,其中一项任务取决于另一项任务。我们测试了这些模式的FigLang2022共同任务,要求参与者预测比喻语言的语言推论标签,同时对推论预测进行相应的文字解释。我们的结果表明,虽然顺序多任务学习可以适应两项目标任务中的第一项,但在第二项任务上表现得不那么好,而在其他任务上也存在过度调整。我们的研究结果显示,文本到文本模型的简单顺序微调是一种超强的跨任务知识转移方法,同时预测多重相互依存的目标。因此,我们的最佳模型在这项任务上取得了(结合的)最高分。