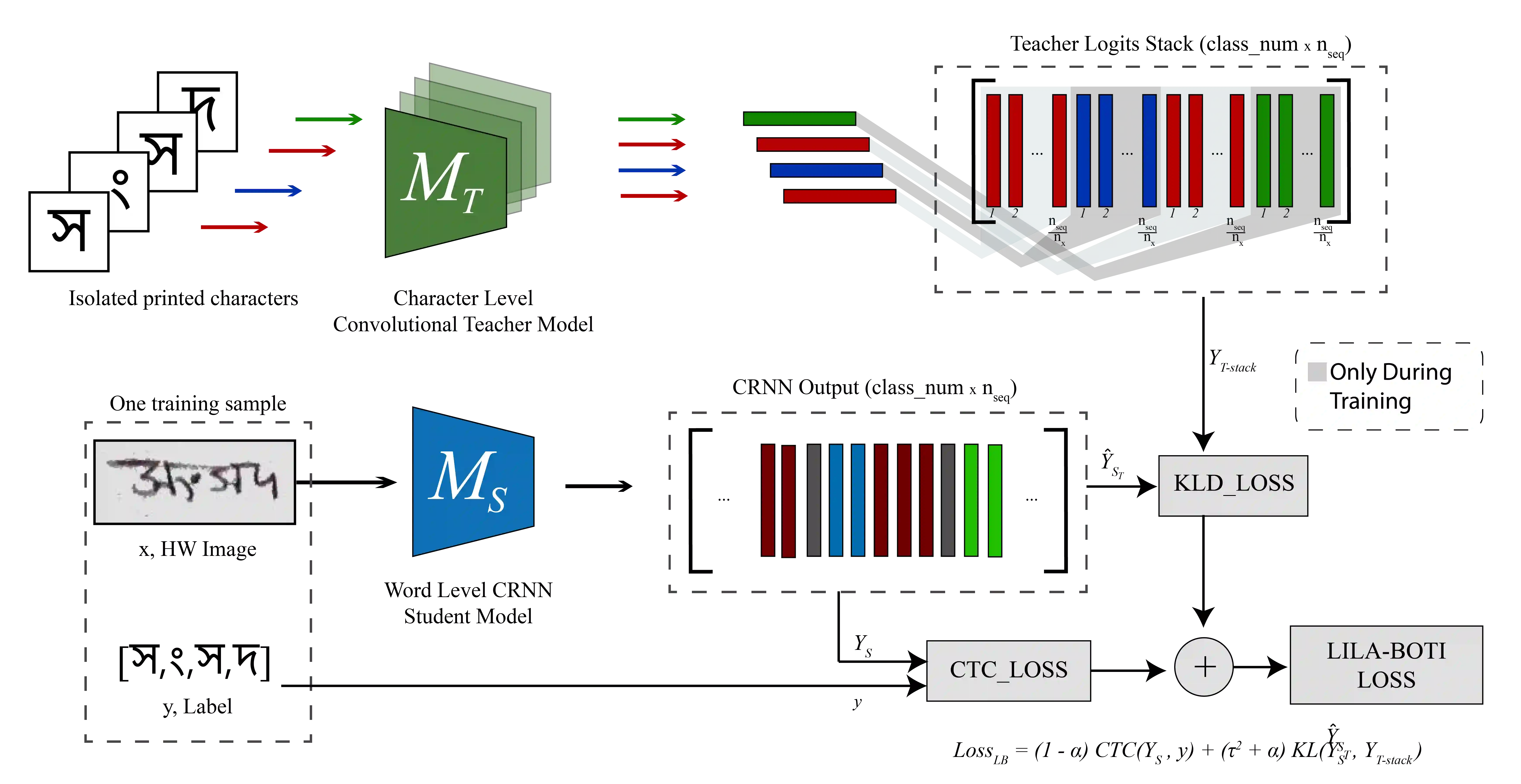
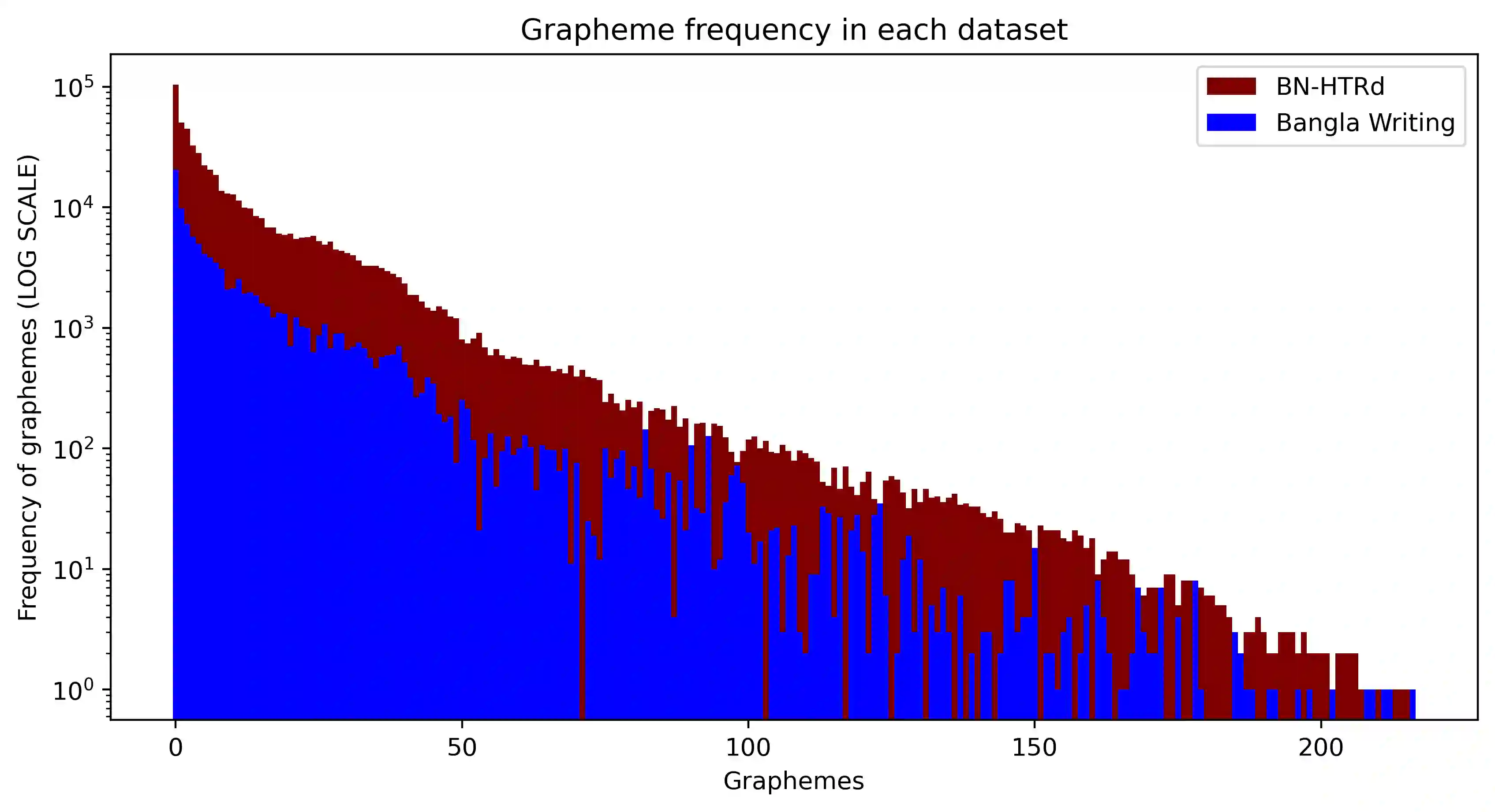
Word-level handwritten optical character recognition (OCR) remains a challenge for morphologically rich languages like Bangla. The complexity arises from the existence of a large number of alphabets, the presence of several diacritic forms, and the appearance of complex conjuncts. The difficulty is exacerbated by the fact that some graphemes occur infrequently but remain indispensable, so addressing the class imbalance is required for satisfactory results. This paper addresses this issue by introducing two knowledge distillation methods: Leveraging Isolated Letter Accumulations By Ordering Teacher Insights (LILA-BOTI) and Super Teacher LILA-BOTI. In both cases, a Convolutional Recurrent Neural Network (CRNN) student model is trained with the dark knowledge gained from a printed isolated character recognition teacher model. We conducted inter-dataset testing on \emph{BN-HTRd} and \emph{BanglaWriting} as our evaluation protocol, thus setting up a challenging problem where the results would better reflect the performance on unseen data. Our evaluations achieved up to a 3.5% increase in the F1-Macro score for the minor classes and up to 4.5% increase in our overall word recognition rate when compared with the base model (No KD) and conventional KD.
翻译:字面手写光学字符识别( OCR) 仍是孟加拉语等形态丰富语言的一种挑战。 复杂性来自大量字母的存在、 存在几种异丙形形式以及复杂组合的外观。 一些图形化的出现并不经常,但仍然不可或缺, 因而为了取得令人满意的结果, 需要解决阶级不平衡问题。 本文通过引入两种知识蒸馏方法来解决这个问题: 通过命令教师透视( LILA- BOTI) 和超级教师LILA- BOTI 来利用孤立信件累积。 在这两种情况下, 革命性常规神经网络( CRNNN) 学生模式的培训都是以印刷的孤立字符识别教师模式获得的黑暗知识为基础的。 我们用\ emph{ BN- HTRd} 和 emph{ BanglaWriting} 来进行跨级数据测试作为我们的评估协议, 从而形成一个具有挑战性的问题, 其结果是更好地反映隐性数据的性能。 我们的评估达到3.5%, 在常规等级中, K1- Macro 将常规等级提高到4.5, 并在普通等级中, K- masion 提高 K- d 标准, K- d 和 K- d 提高 K- d 标准分级中, K- d 达到3.5 和 K- d) 在常规等级中, 和 K- sqro) 在常规等级中, 在常规等级中, 我们的评分级中, 达到3.5- d