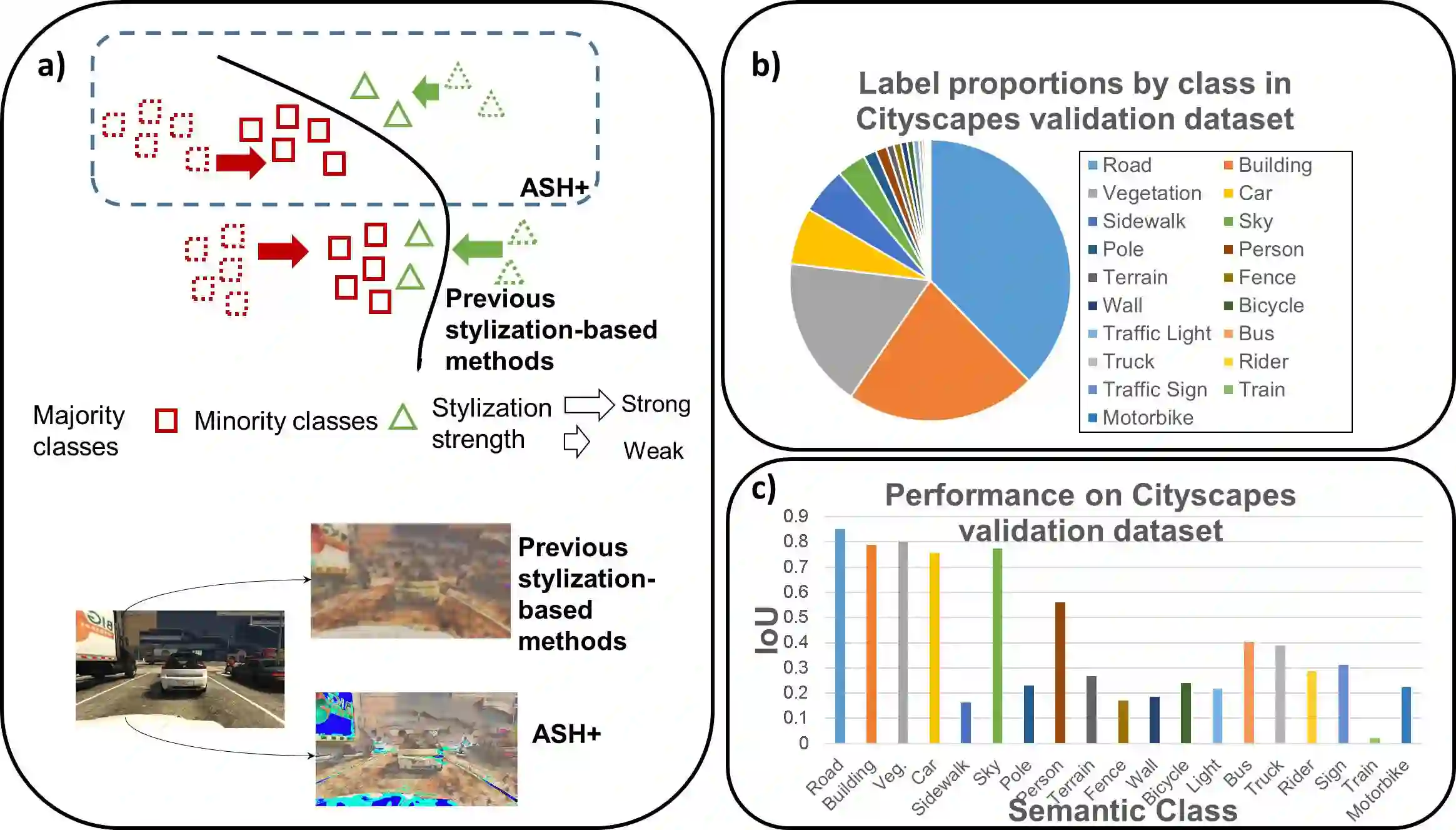
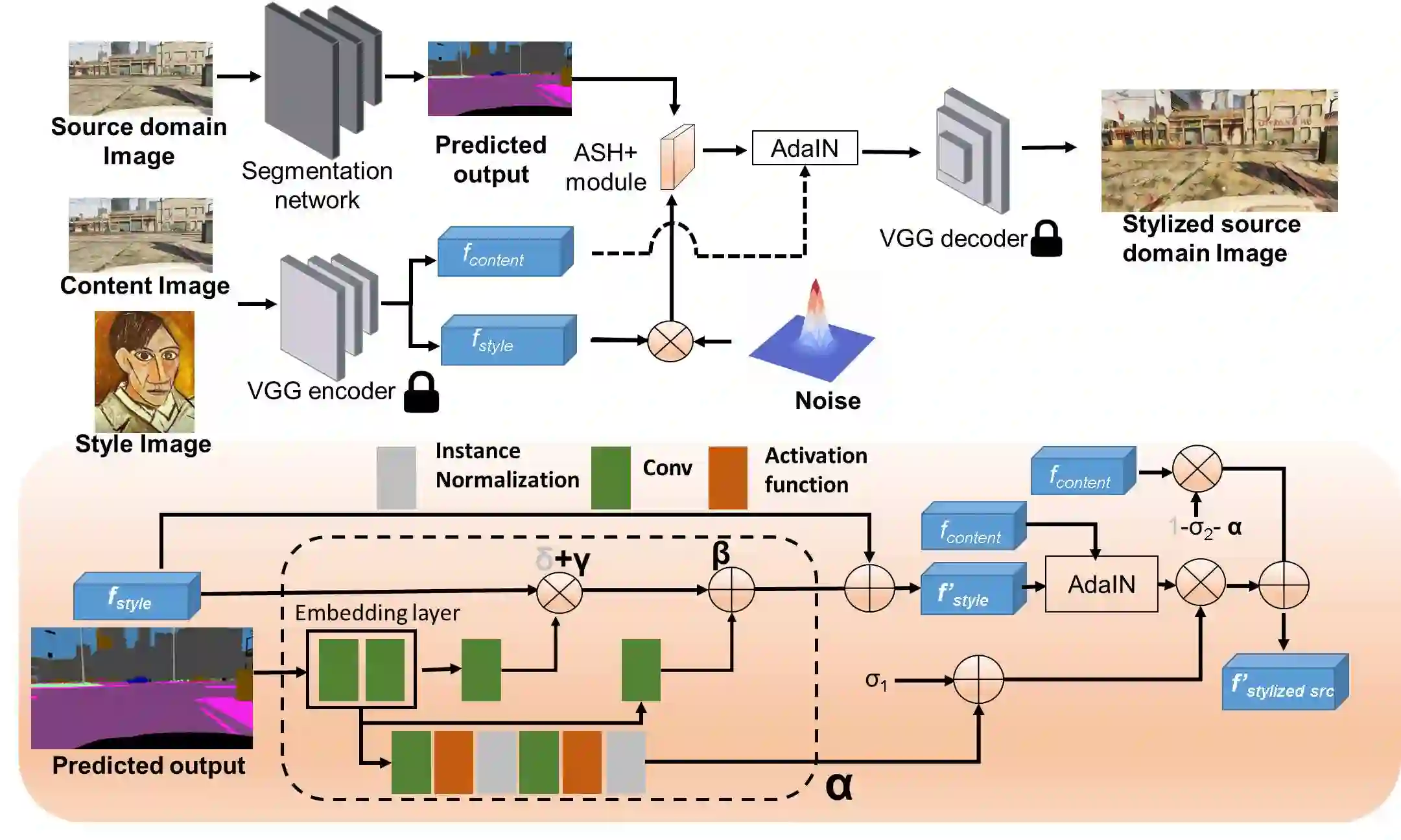
Obtaining sufficient labelled data for model training is impractical for most real-life applications. Therefore, we address the problem of domain generalization for semantic segmentation tasks to reduce the need to acquire and label additional data. Recent work on domain generalization increase data diversity by varying domain-variant features such as colour, style and texture in images. However, excessive stylization or even uniform stylization may reduce performance. Performance reduction is especially pronounced for pixels from minority classes, which are already more challenging to classify compared to pixels from majority classes. Therefore, we introduce a module, $ASH_{+}$, that modulates stylization strength for each pixel depending on the pixel's semantic content. In this work, we also introduce a parameter that balances the element-wise and channel-wise proportion of stylized features with the original source domain features in the stylized source domain images. This learned parameter replaces an empirically determined global hyperparameter, allowing for more fine-grained control over the output stylized image. We conduct multiple experiments to validate the effectiveness of our proposed method. Finally, we evaluate our model on the publicly available benchmark semantic segmentation datasets (Cityscapes and SYNTHIA). Quantitative and qualitative comparisons indicate that our approach is competitive with state-of-the-art. Code is made available at \url{https://github.com/placeholder}
翻译:我们的目标是减少实际应用中模型训练所需的被标记的数据量,因为获取足够标记数据不切实际。因此,我们解决语义分割领域泛化的问题。最近的领域泛化方法通过使图像的颜色、风格和纹理等领域特定特征多样化来增强数据多样性。然而,过多的样式化甚至均一化的样式化会降低模型性能,尤其是在对抗极具挑战的小类像素分类时。因此,我们引入了一个模块 $ASH_{+}$,根据每个像素点的语义内容来调节样式化强度。在本文中,我们还引入了一个参数,用于平衡样式化的元素和通道上的比例,与样式化前的源领域特征在样式化后的源领域图像中的比例。这个学习的参数取代了经验确定的全局超参数,可以更精细地控制输出的样式化图像。我们进行了多次实验来验证我们提出的方法的有效性。最后,我们在公开的基准语义分割数据集(Cityscapes 和 SYNTHIA)上评估了我们的模型。定量和定性比较表明我们的方法是与最先进的方法竞争性的。代码可在 \url{https://github.com/placeholder} 上获得。